#Disclaimer: Dated Content
# In 2023 this website was built using Hugo version 0.111.3 from March, 12 2023. Hugo is in very active development and it changes often, therefore many of these examples might not work in newer versions. The 2023 documentation for this version is on the Wayback Machine.
# Of course you can find the latest version here along with the current documentation.
# I have a confession. I already spent the past 2 weeks figuring out Hugo and setting up my new website. It’s actually going really well. But figuring out all this new stuff kind of burns me out so I haven’t had the energy to post about it right away.
# I’ll tell you about it. But this isn’t going to be a tutorial. Somebody else already wrote one. Instead, this is just a story about all the interesting speed-bumps I tripped over along the way. Such as…
#“Installing” Hugo
# Okay, let’s go get Hugo. Huh… all the tutorials keep telling me to install it. I thought it was just a single EXE?
# Oh, it is. The tutorials are just lying… all of them. Developers sure have a hard-on for GitHub these days. The tutorials love telling me to open DOS and type “Git” like it’s 1982. Screw that! It’s the 21st century, I have a perfectly good mouse, and I gonna use it… to click the download link.
# I pressed one button!
 Push button... get program. Coder I am. My brain, big is.
Push button... get program. Coder I am. My brain, big is.#Manually creating a “theme”
# Like any “convenient” program, if you try to run Hugo right away, it won’t work. Wait what? Apparently it needs something called a “theme” first. What a strange thing to forget.
#
Okay… what is a “theme?”
It’s a set of templates.
# …and those are?
# A bunch of HTML files with funny squiggly lines inside them. They’re the parts of the page that can change. They’re placeholders. The stuff outside of them doesn’t change and will be on every page of the website.
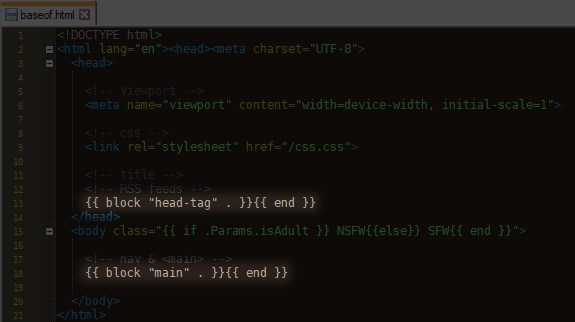
# Uh… which files?
# These ones. You can add more. But these are the ones you actually need.
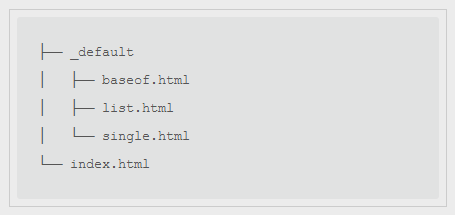
# Pretty much every tutorial about using Hugo skips this part, and instead tells you to just download an existing theme and call it a day. Yes that works and it’s easy, because it creates these files for you, but that’s not enough for me… I need to know what goes inside them!

#
… because I already designed my website. I know exactly how I want all the HTML and CSS to look. So I want to build my own hugo theme templates.
# Okay. It looks like I can just copy this minimal hugo-starter theme and build off of that. I’ll just download it from GitHub…
 by using the big green button everybody forgets about...
by using the big green button everybody forgets about...
# … and copy its “layouts” folder, replacing the one in my hugo folder. Now when I run Hugo’s server it actually shows something.
 An actually functioning program... Oh boy! I can work with this!
An actually functioning program... Oh boy! I can work with this!#Test Server Script
# Okay, what is this “server” I just mentioned? Apparently Hugo has one built-in so I can test a website right away without having to upload it. It also has “live reload” which refreshes pages while whenever I modify anything, so I can see my website change in real-time. For convenience I just put this into a .CMD file so I can just double-click this with my mouse when I want to see my website:
start "" http://localhost:1313/
hugo server
pause
# It does 2 things.
- It opens a web browser with that URL
- It starts Hugo’s server
# These commands might look out-of-order, but Hugo halts the script until I close it, so I need to start the web browser first.
# I also add “pause” at the end to keep the window open in case anything goes wrong with Hugo. That way if there’s an error the window will stay open so I can actually see it.
#Hugo build script
# Seeing the website’s neato and all… but where are the HTML files? You know… the whole reason for using Hugo?
# Apparently Hugo’s server just holds everything in RAM. You get HTML files by running Hugo by itself.
Hugo
# That’s literally all you type. A folder called “public” will suddenly appear with the entire website inside.
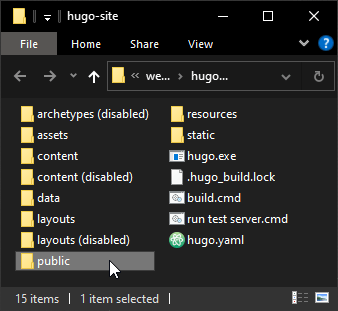
# Okay, so I actually did add a couple minor things. Here’s what they do.
hugo --buildDrafts --cleanDestinationDir
pause
#Layouts, Partials, Shortcodes
# Now I just need to look up how to modify the files I copied from the hugo-starter theme. Here’s where the real learning curve starts, but this looks like a pretty good tutorial.
# … and to look up anything else, the gohugo.io website is basically the Hugo bible. I’ve been using it a lot.
#Moving my Projects Into a “content” folder.
# My old website put all the projects into a folder called content. And since I don’t want to break all the links to my website (more than I have to) I want to do the same thing with this website.
# Ironically Hugo already has a folder called content, but that folder won’t actually appear inside the website it generates. Instead Hugo treats it like the “root” of the website. The things inside of it are what get added, so what I actually need to is put another “content” folder inside of Hugo’s content folder.
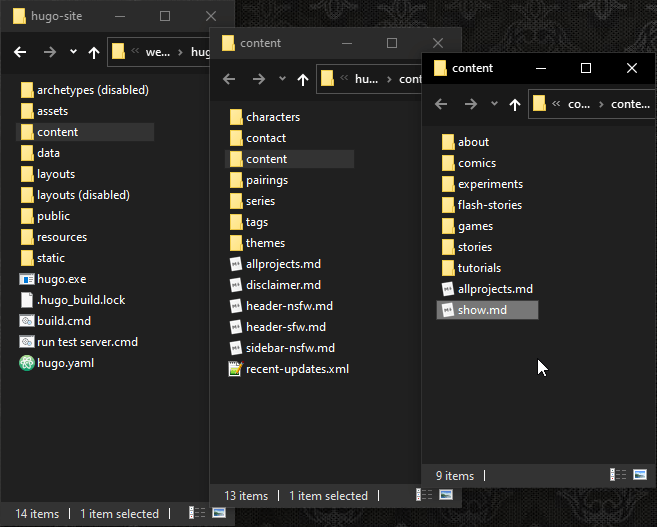
# It’s like this:
My-hugo-site
├─assets
├─content
│ └─content
├─data
├─layouts
├─public
├─resources
└─static

# Hugo doesn’t really like me doing this. I mean, it’ll work. The website will have a “content” folder now, but Hugo will stop making useful assumptions.
# If you have this option turned on in Hugo’s config file, then it assumes that all the folders you create inside of its default content folder are sections of your website. But if I put everything inside of a second content folder, then Hugo wants to assume that my website only has one section and assumes this one section is named “content.”
# That’s not a problem. I’ll just turn off that option, and manually tell Hugo what section each page is supposed to be. But it’s kind of ditching the training wheels early.
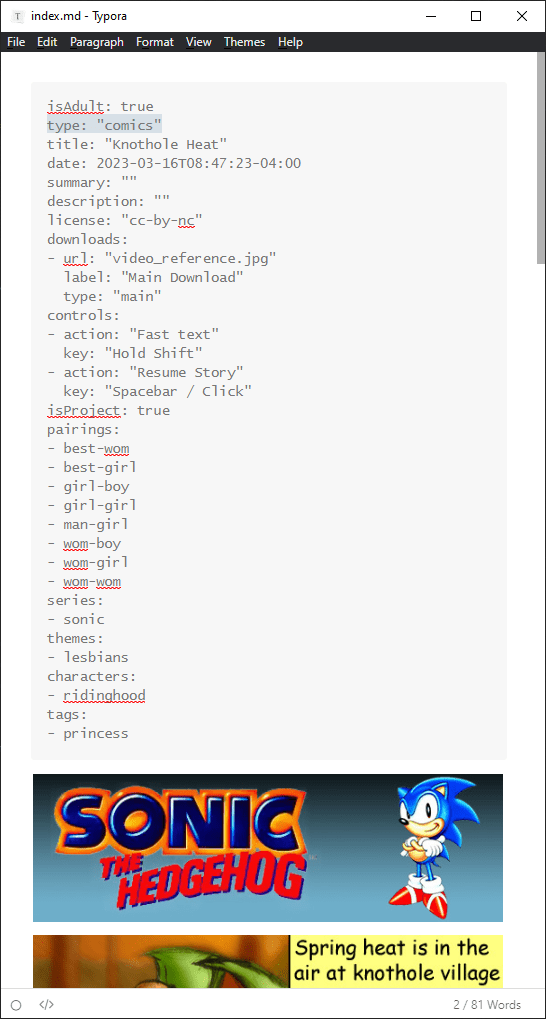
#Using .htm files instead of .html
# Ooh, what’s this? It looks like you can tell Hugo to use a .htm file extension for all the pages. Maybe I can recreate my old website’s structure after all!
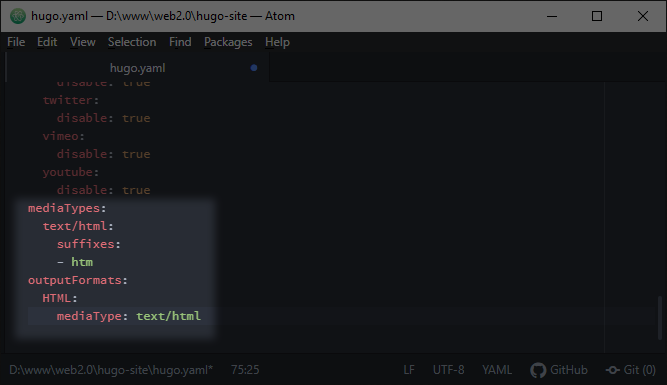
# Wow, that broke a bunch of things.
# I guess I need to rename all the templates to .htm as well… and do a text replace to change .html to .htm in all the MarkDown content files.
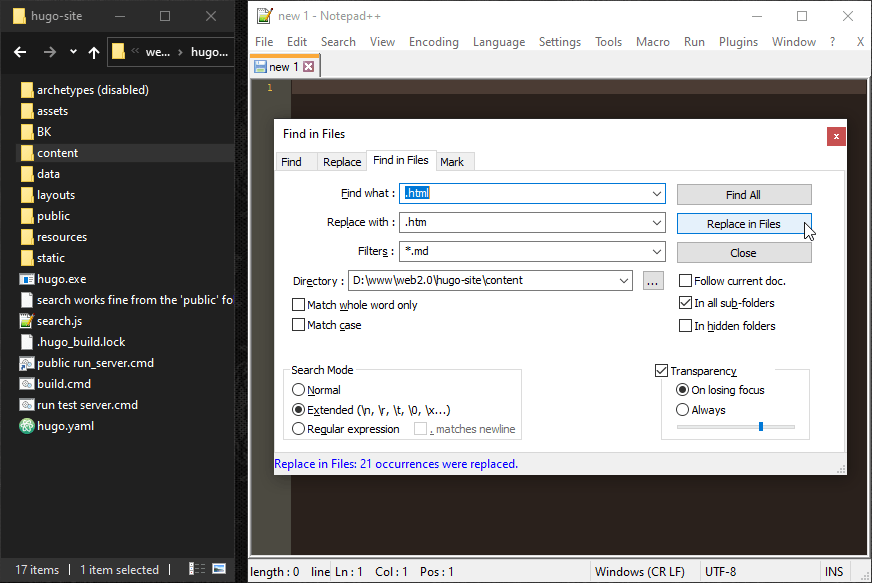
# Okay it’s working, but now my thumbnails have weird URL’s in their links.
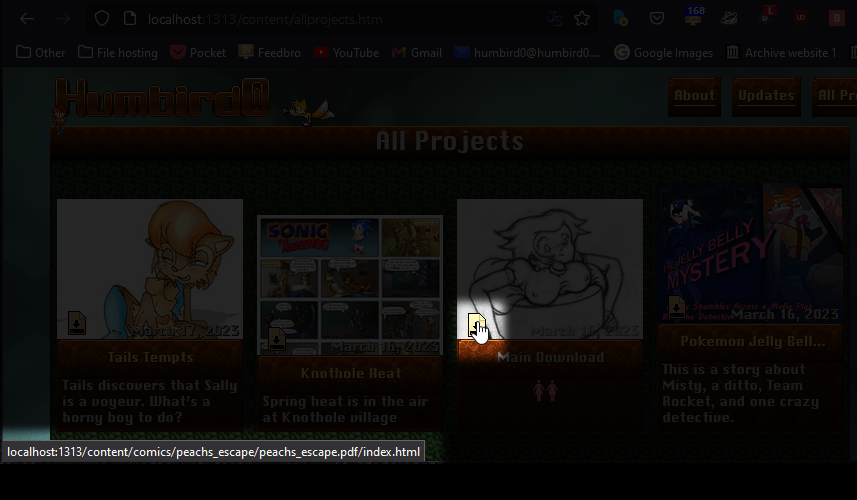
# Oh, so now I don’t have to add the filename anymore? That’s weirdly inconsistent compared to Hugo’s default behavior. But it’s working now.
# Ah, and I can also tell Hugo to use a different filename besides “index.” In my old website a lot of my projects used “content.htm” Now we’re really getting close to recreating the old site’s file layout.
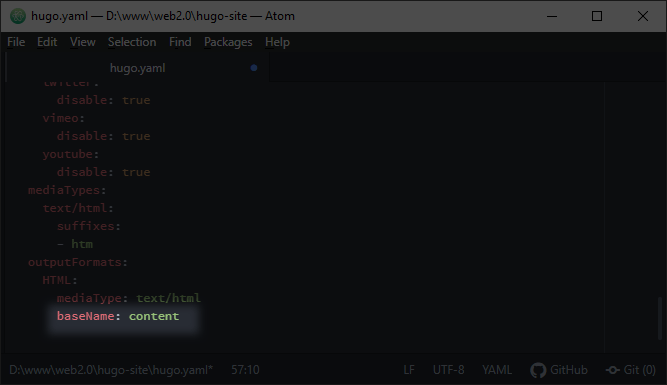
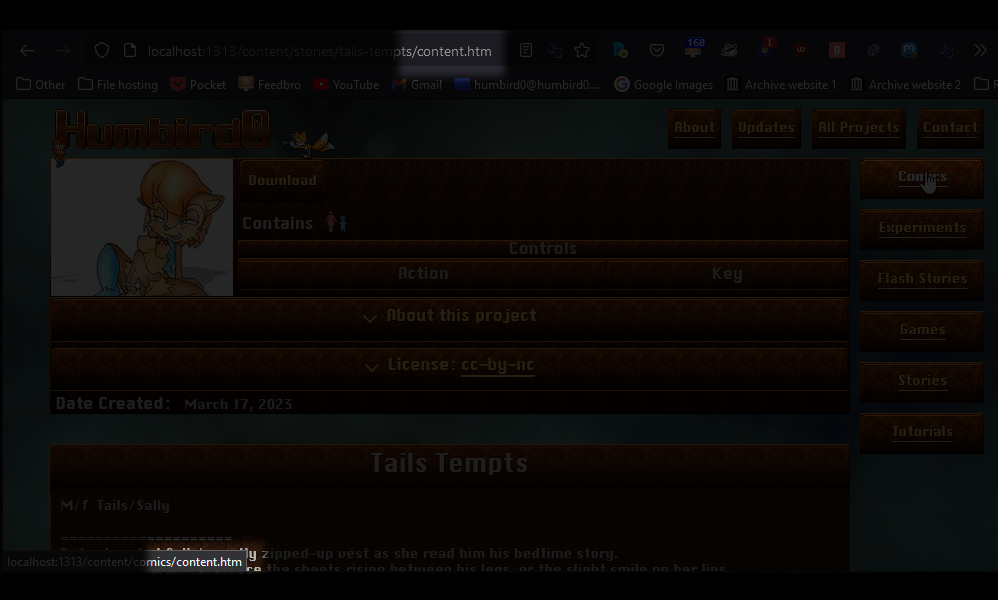
# Of course I don’t want every file to be called “content.htm” and it looks like Hugo is mostly respecting my custom-named files for things like the header and sidebar, so I know it is possible.
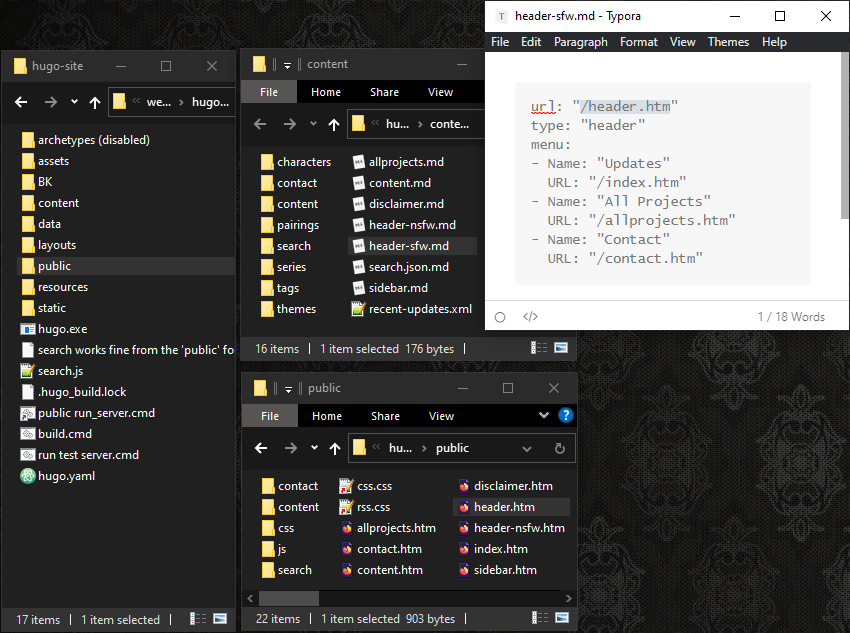
#
… except for the decoy page. I do want that to be named “index.htm”, because that’s the typical place where a normal website would start, and therefore the first place people would look. I can rename a file the same way I would move one. Just put a Markdown file in the folder where it would normally be, set its output “url” to the new filename, and tell it which layout to use by setting its “type”. So in this case setting the type to “updates” refers to the file /layouts/updates/single.htm
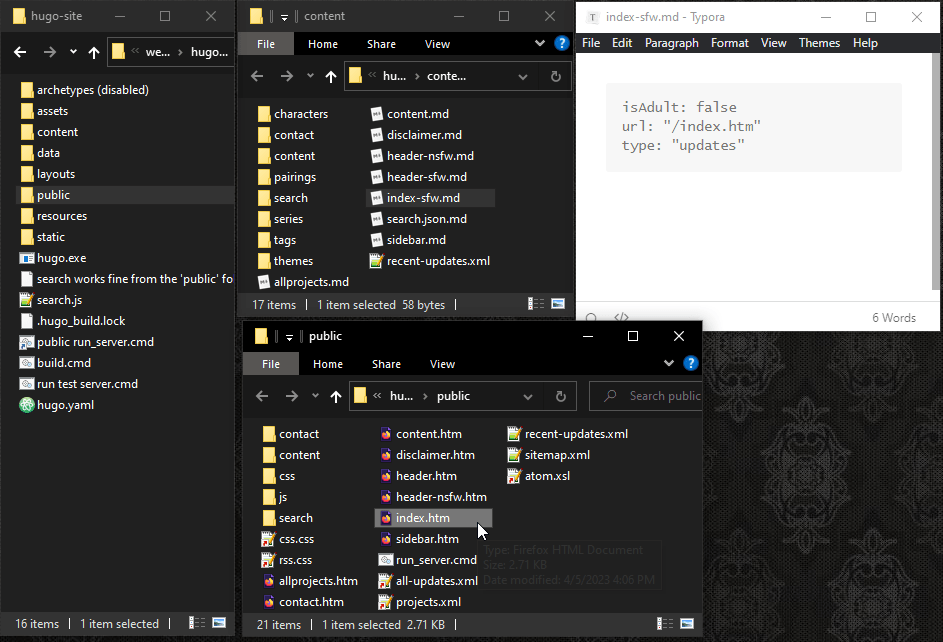
# I’ll figure out a better place for that search box later.
#Removing default pages
# Okay, but for some reason Hugo adds an extra default page next to the two pages I defined. I guess it assumes that every folder should have an “index.htm” inside it. (I told it to use “content.htm” as the default name in this case)
# So what’s inside of this extra page, anyway?
# It’s a generic list of the default pages for each folder inside of this one.
# Okay… how do I get rid of it? I don’t want a default page or an “index.htm” in here, because I want people to be able to browse this folder.
# Hmm… can I at least modify it? A “list” page is normally defined using a “_index.md” markdown file, so let’s add an empty one.
# Oh hey! That removed the default page!
#Can’t use archetypes anymore. Oh well. Wasn’t really planning to rely on them.
# That also means that Hugo’s archetypes feature won’t work right. Nothing important. Just another convenience. Normally you can tell Hugo to create a new page for your website and it will automatically copy over some predefined settings for that page. But when I’m putting everything inside a 2nd “content” folder it gets kind of confused.
# Luckily I already have a content management program for my website. The same one that I created for my previous website, so… it’s not like I was going to rely on Hugo for this anyway.
#Section galleries. Auto filtered lists based on hugo “type” in _index.md
# Okay, let’s figure out how to make my thumbnail galleries… by looking it up. Apparently Hugo assumes that every page is either a “list” or a “single.” So I guess I need a list. Here’s the simplest possible list. It literally creates a list of links.
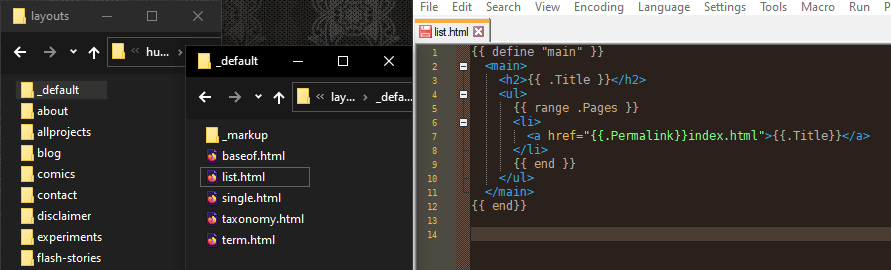

# So I’ll just replace that link with my thumbnail.
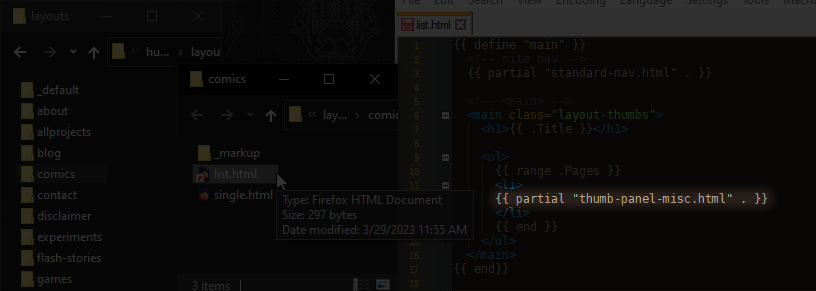
# “WTF? Did you just draw the rest of the fuckin’ owl? or something?”
# No I used something called a partial template. It’s a template that you can call from another template. This means I can put a thumbnail on any page, not just the galleries, by just sticking this in there.

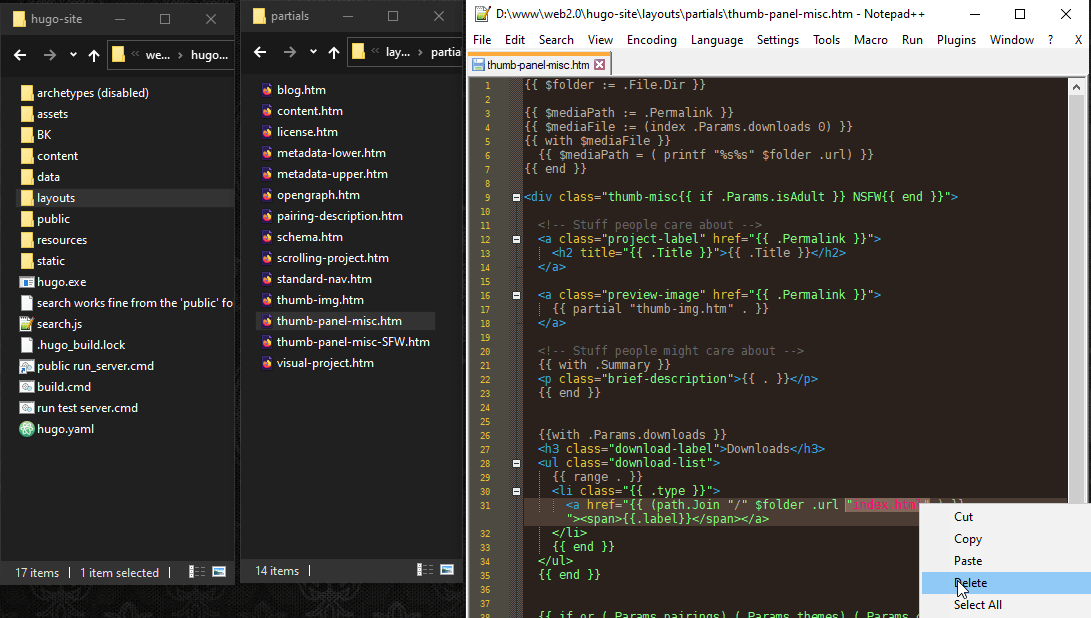
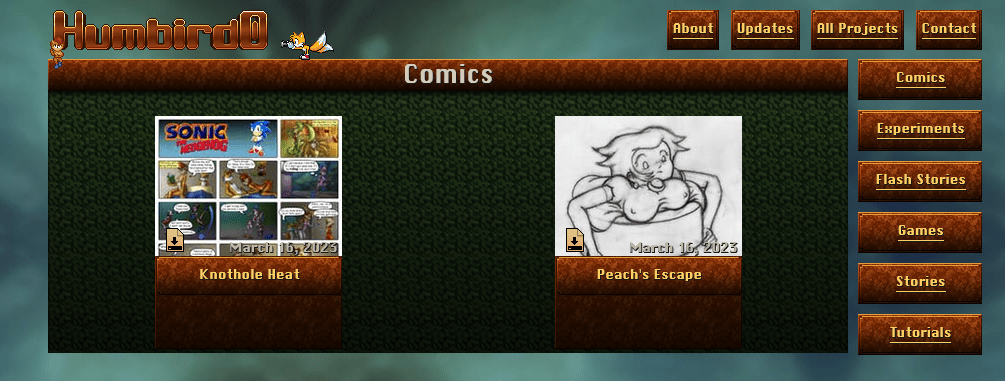
# So what’s inside of “thumb-panel-misc.html?” The HTML that actually makes up a thumbnail.
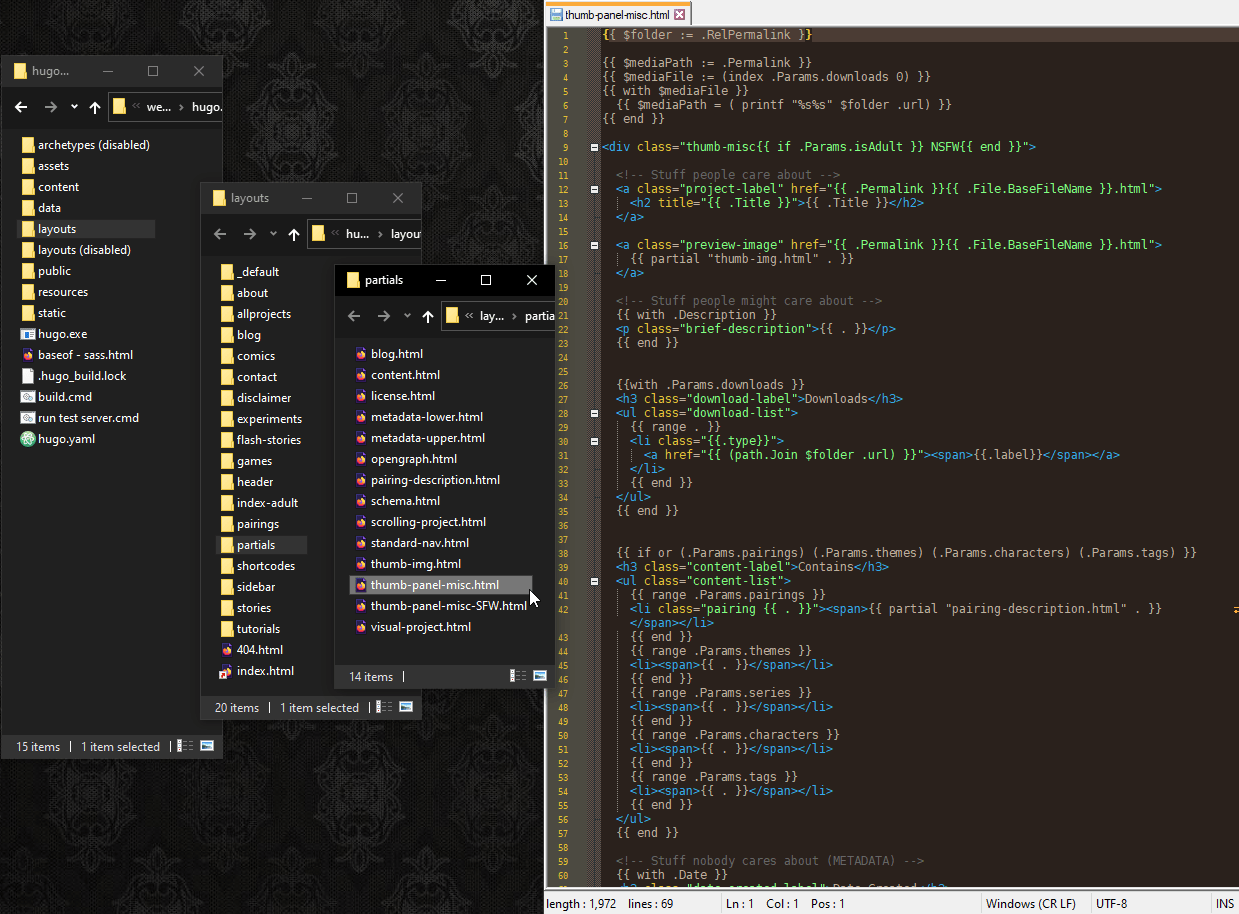
# When Hugo generates the website files, the contents of this file basically gets copied and pasted where that line was. And as you can see I can call partials from other partials. So I can always go deeper.

#Menus in the front-matter, Manually choosing the Header HTML location
# I think I’ll tackle the website’s header next. Since these buttons will never change I could just dump everything into its template. But the actual content of a page is supposed to be separate. Hugo uses MarkDown files for that. Putting content inside the template would make it hard to find.
#
But if I create a list of links using MarkDown I’ll just get generic HTML. That would function, but it would not be semantic. These buttons are for navigating the website, so I had originally planned to wrap them inside a <nav> tag.
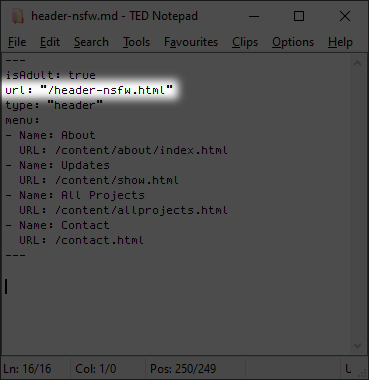
# So I’ll define the menu in the page’s front matter.
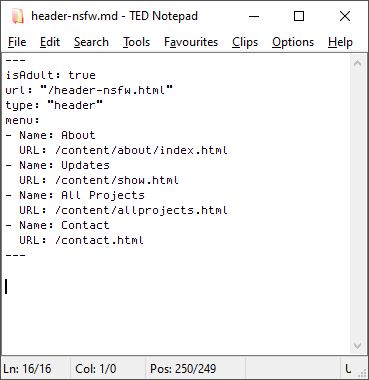
#
The stuff between the --- are basically this page’s settings. Its template can access this information, so I can turn it into any HTML I want. Specifically, this.

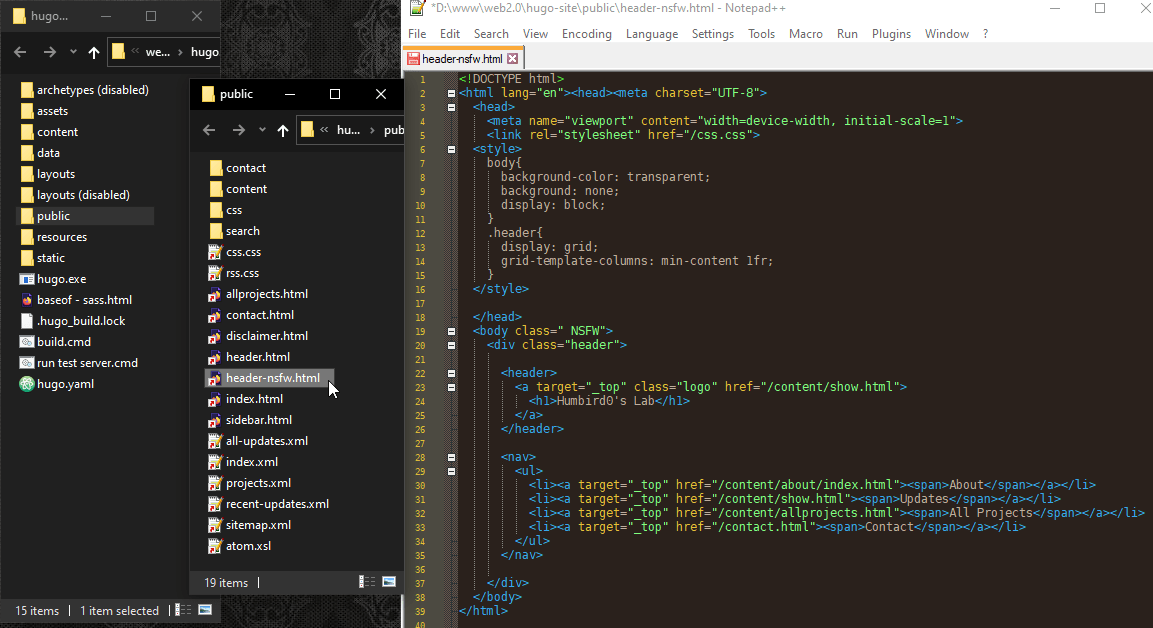
# Which was generated by this template.
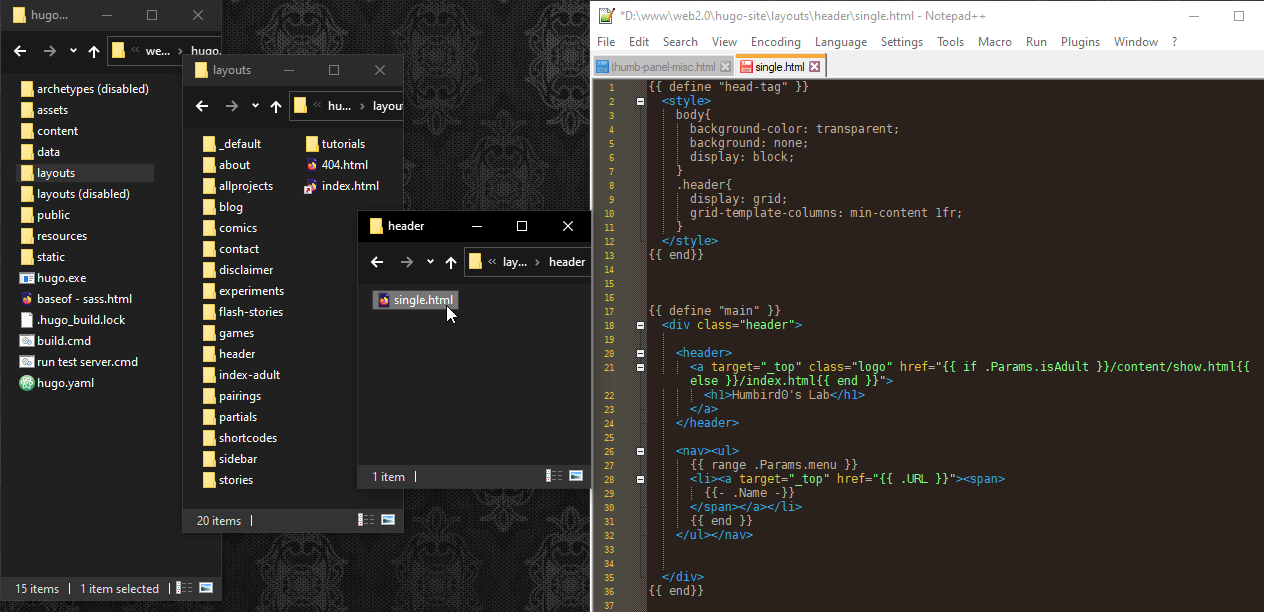
# The header’s HTML file also needs to be in a specific place with a specific name. I can control that manually with the “url” setting.
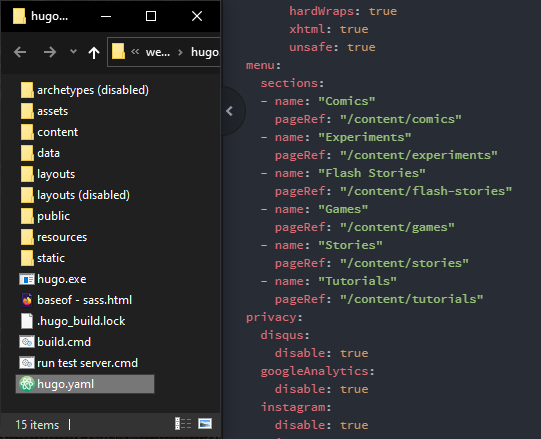
#Menus in hugo’s config, and the website’s sidebar
# Now let’s figure out the website’s sidebar. Unlike the header, these buttons do change.
# But since I can’t rely on Hugo to figure out what sections my website has, I’ll just spell it out directly in the website’s settings.
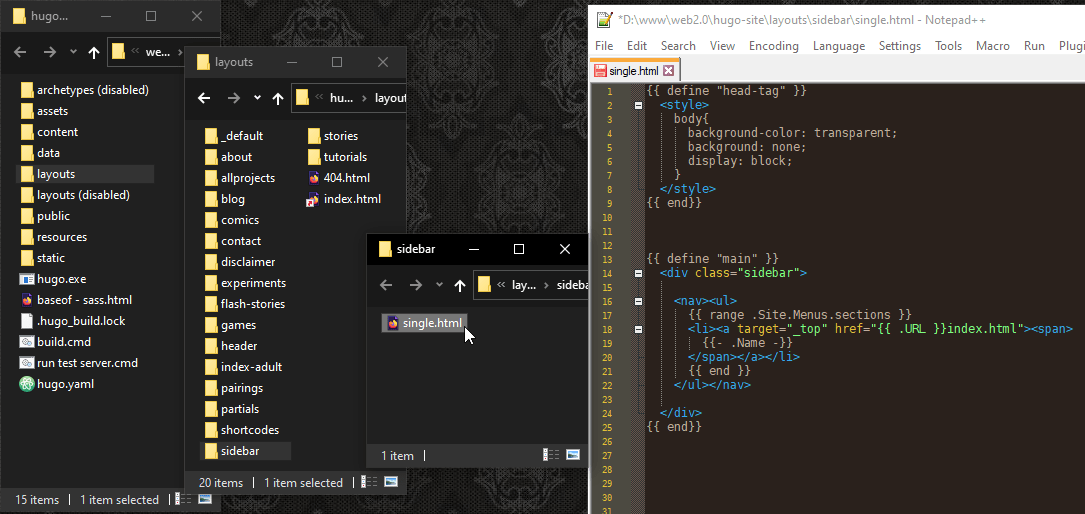
#
The sidebar’s template accesses this setting from the .Site settings instead of anything that’s actually on its page. It completely ignores its own front-matter.
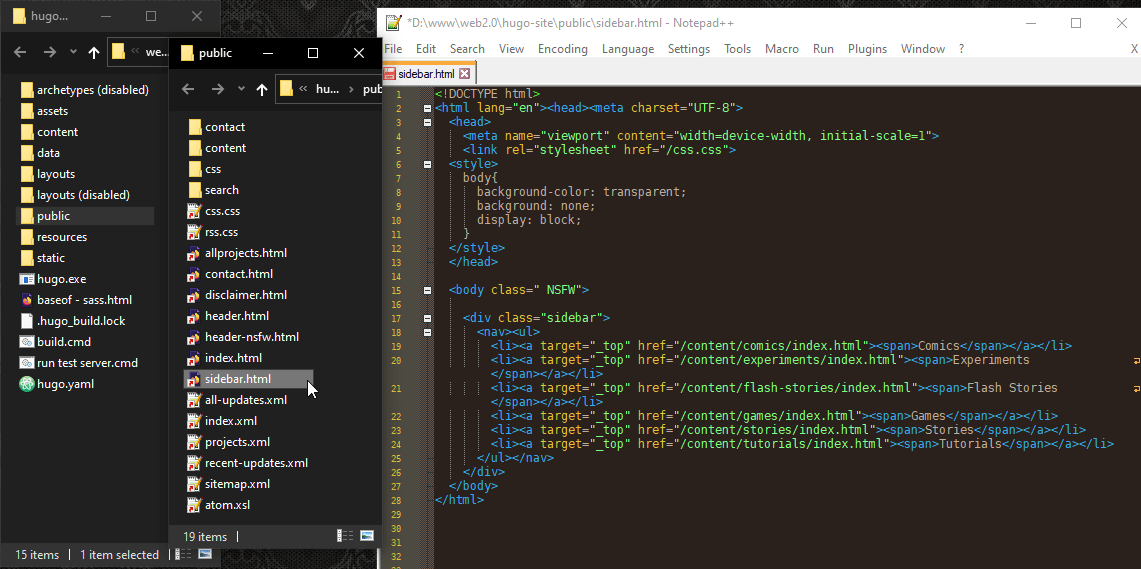
#
And here’s the HTML that gets created. Again I’m wrapping the list in <nav> so that things like screen-readers know that this list is for navigating the website.
#Manually loading the “about” files.
# My projects usually have detailed “about” sections. These are long enough that it makes sense to store them as a separate file. In the past I hand-wrote separate HTML files for these. But if I ever change the way the website presents things like screenshots, I don’t want to have to manually go back and change all of these files, so I’m going to use markdown for them instead to force them to be simple. I already figured out how to make CSS recognize groups of pictures so I don’t have to manually write unique sets of HTML tags each time. The idea is to separate the content from the instructions about how to display it. Markdown’s limitations seem like a good way to force myself to keep those instructions out of the HTML as much as possible.
# So, uh… how do I add other files to a page in Hugo?
#
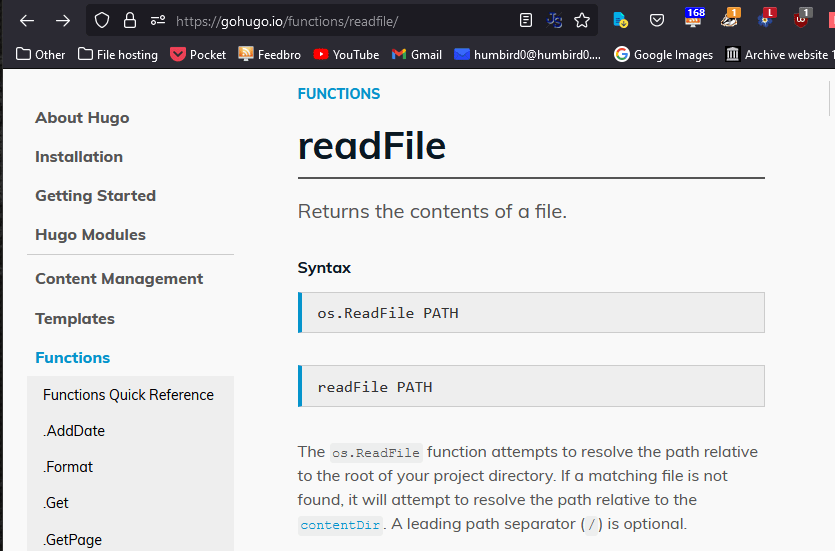
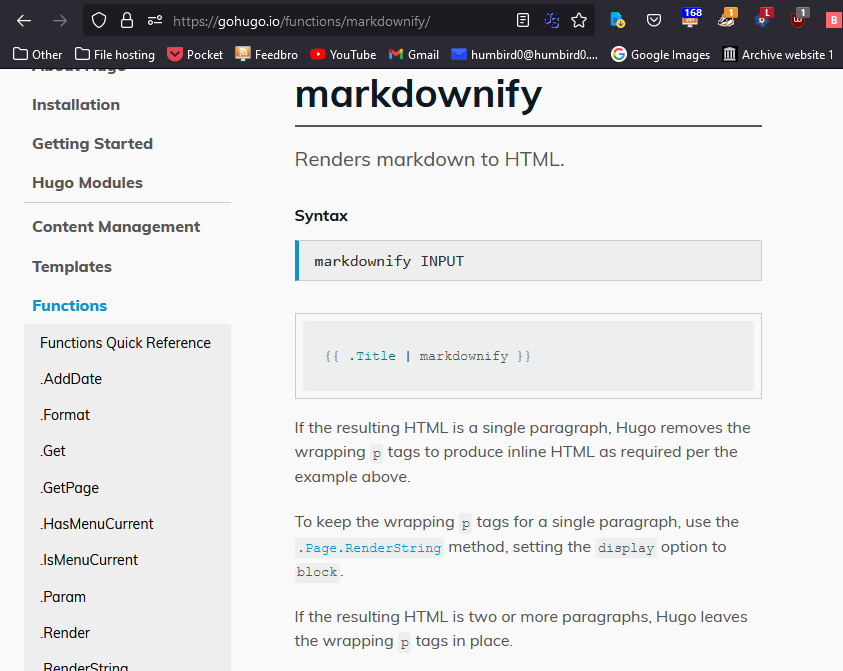
It looks like I can use readFile and markdownify commands to get a file and manually convert it from markdown into HTML.
# Of course I might want to load files for other reasons, such as displaying the text of a story. So I’ll make this into a “partial” template. It turns out that it’s possible to send multiple things to a partial as inputs. If you’re a programmer, this is kind of like a function call with parameters.
# Anyway this partial template needs to know 2 things. The name of the file to load, and it needs information about the current page to find out what folder we’re in.
#
Normally you could use .File.Dir in a Hugo template to get the folder. But since I send the page’s information in a variable named “this” I use .this.File.Dir instead. (Make sure that you put a period before “this”)
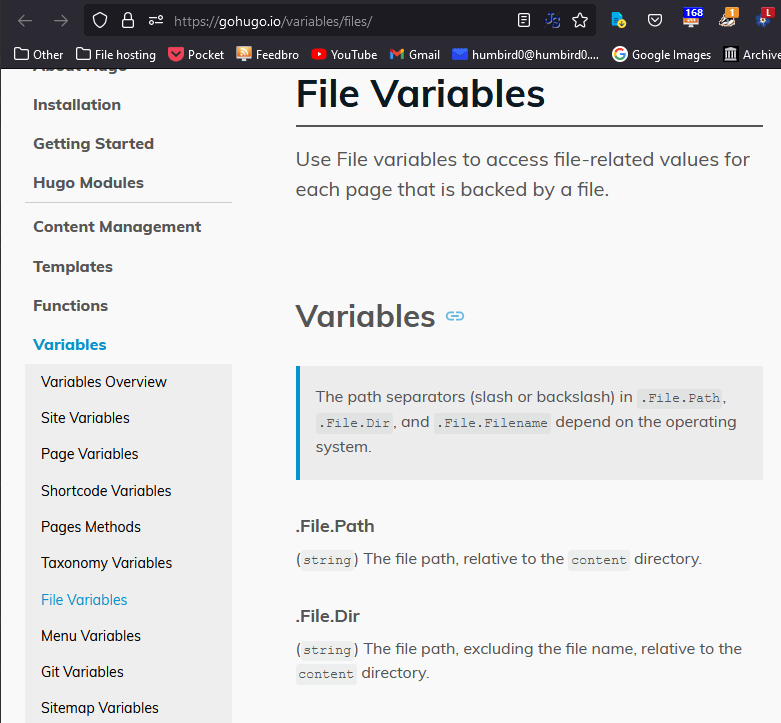
#
So I take the folder and attach the filename path.Join, like this: (path.Join .this.File.Dir .file)
# Okay, so I have a file path. How do I see what’s inside the actual file? Easy, just pipe the path into readFile. A “pipe” is a vertical bar. It’s that key just above the “enter” key on most US keyboards. It treats the output of one thing as the input for another thing.
# But now my $temp variable just contains raw text. To treat this text as markdown and convert it into HTML I pipe it to the markdownify command.
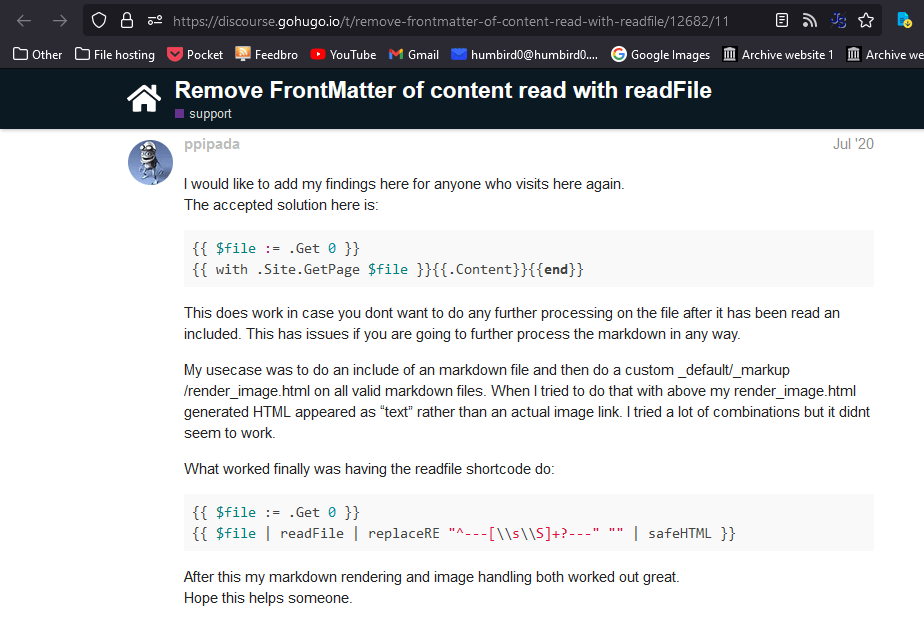
# … also there’s a “replaceRE” command to remove any front-matter from the about.md file using a regular expression. No, I’m not some kind of super-genius who actually knows regex. I just googled it like everybody else.
#Shortcodes and the imgSource widget
# So what about more complex things? I usually like to mention the pictures and artists that inspired me. A simple image in a markdown file isn’t going to cut it. I want to use some fancy HTML.
# But earlier I just said I didn’t want to put elaborate HTML in my markdown files.
# Hmm… it looks like Hugo has something called shortcodes. They’re like partial templates that you put into the content instead of the templates. It acts like a placeholder where more complex HTML will go.
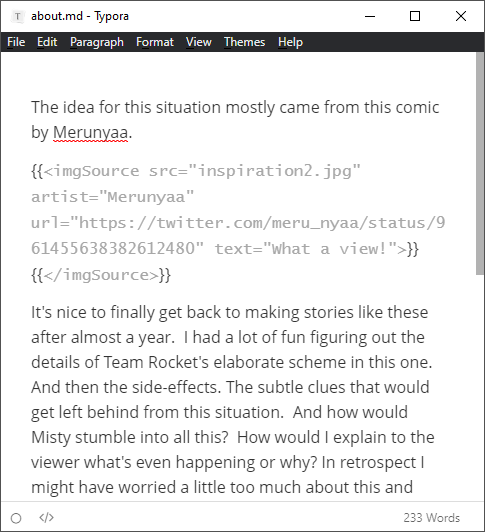
# It’s a great idea, but this syntax is kind of funky.
#
If I try to migrate my website to something else in another 10 years. No other program on Earth is going to know what the fuck to do with this shortcode thingie in my markdown. I wish I could just use XML for this instead. If I converted a markdown file with XML into an HTML file, the result would just be a normal HTML file with a custom tag, and browsers treat those like a <span> tag. HTML itself is basically XML anyway. Lots of things understand XML.
#Manually loading text stories. (use a shortcode to load a file and automatically display it as markdown)
#
My filthy fanfics, er… short stories are written as plain text files. If I tried to copy them directly into the HTML all the carriage returns would disappear and you’d just see an ugly wall of text.
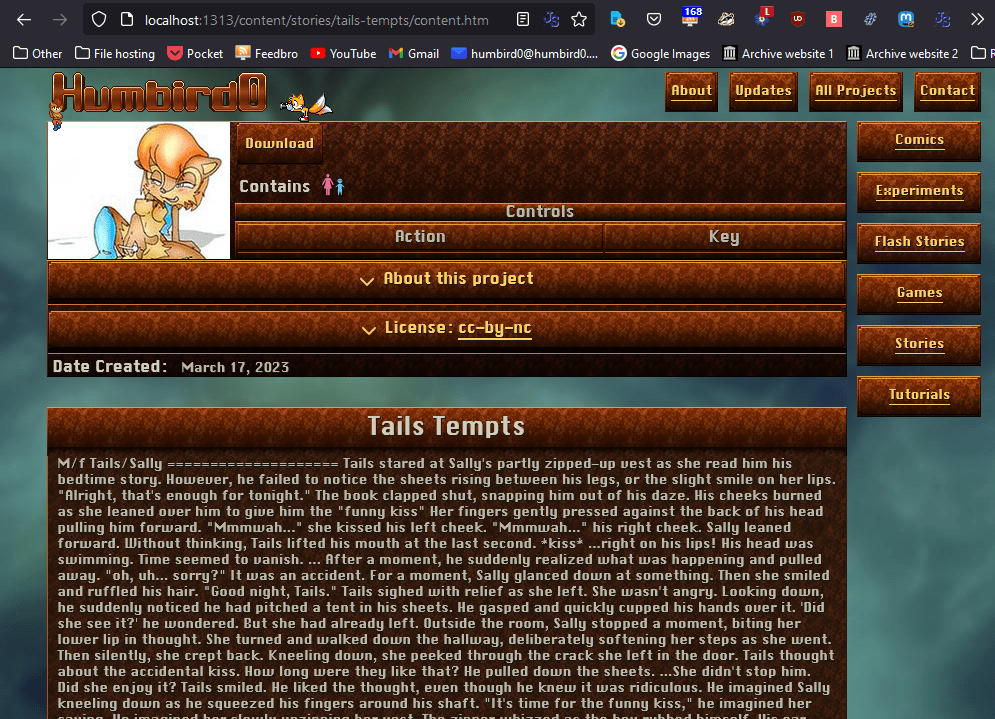
# But… MarkDown does pay attention to carriage returns. What if I just lied and told Hugo this TXT file was MarkDown?
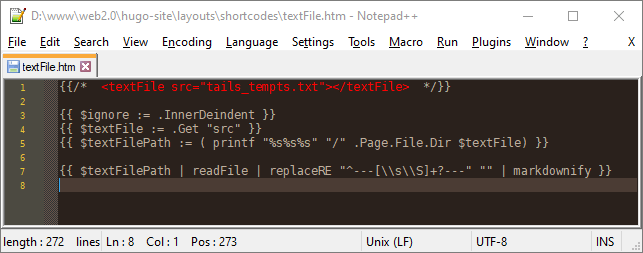
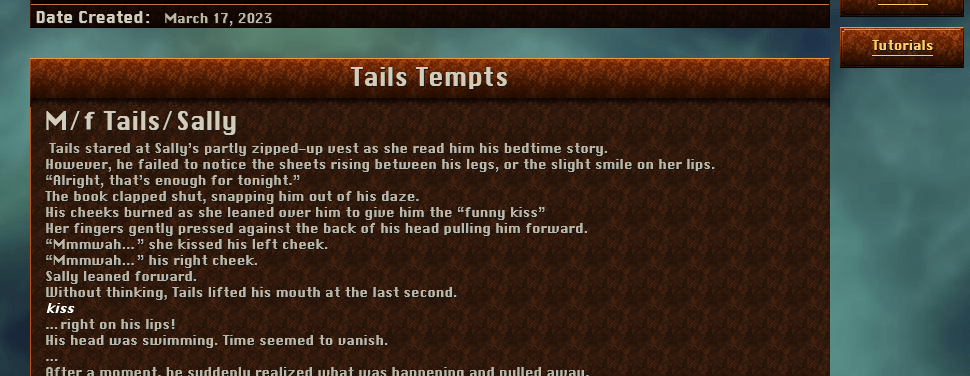
# Oh… it’s treating the story’s content warnings as a header because I happened to put a line under them. I suppose I could just add an empty line between the text and line. Oh wait. Instead of treating the text like markdown, I could just…
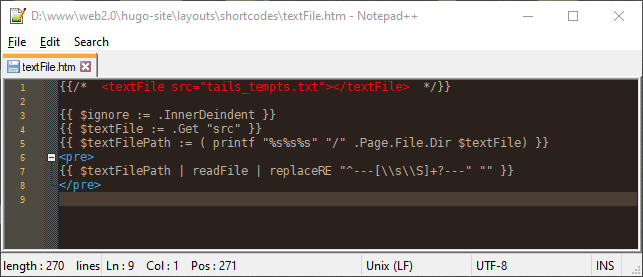
#
… put <pre> tags around it. It’s was written to be text, then let it be text.
#Table of Contents, config settings, template, “sticky” CSS, why fill the area under the TOC
# I love that thing where some websites make the table of contents stick on the screen when you scroll down. It’s actually really handy, especially when looking through documentation.
#
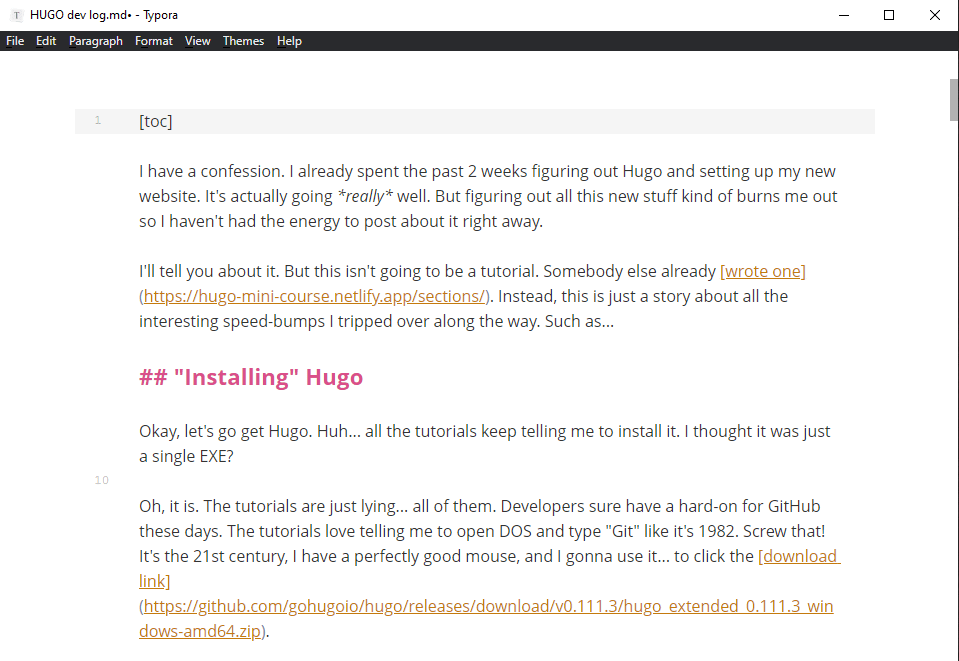
Some markdown editors like Typora let you easily add a table of contents just by typing [toc]. I’m not sure if that’s a Markdown thing or just a unique feature. For example, here’s the one for this Hugo dev log.
# Just typing this…
# Turns into this.
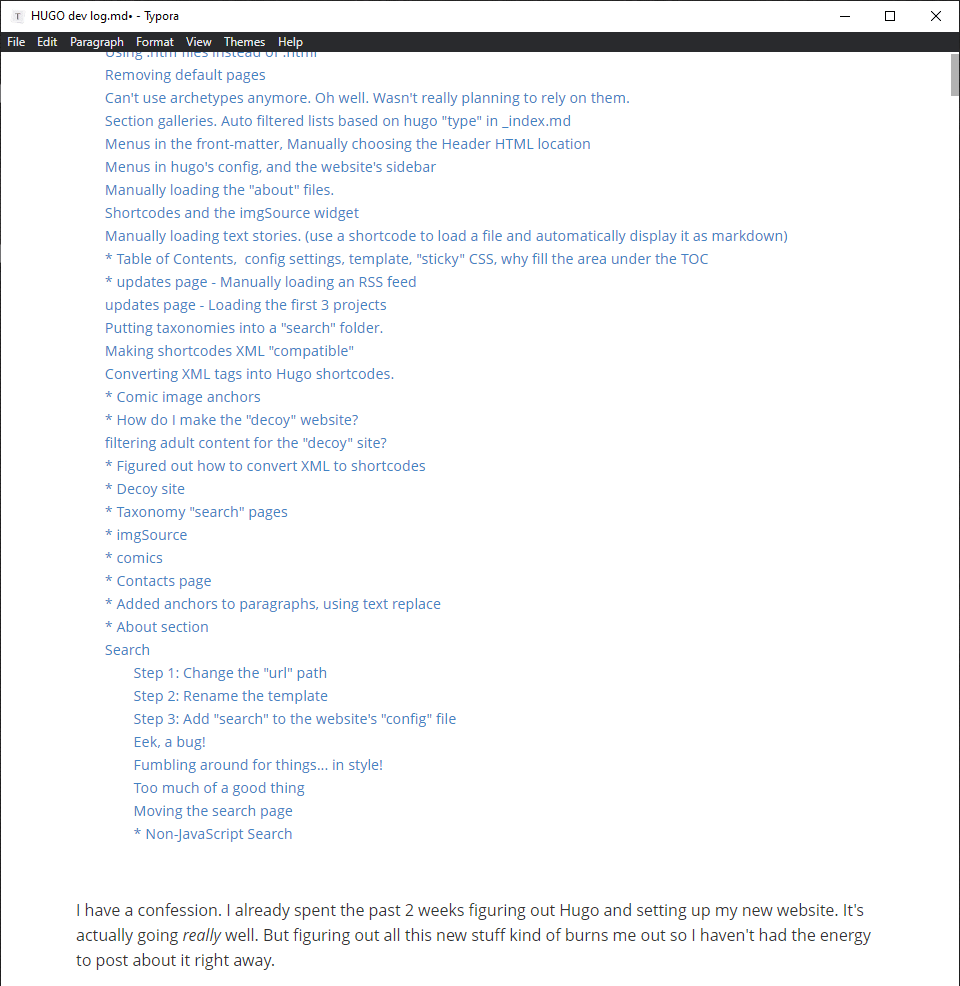
# Wow, I… might have gone a little overboard with this whole Hugo dev log thing. (I put a * in the headers of the parts I haven’t finished writing yet)
#
Aaaaaaanyway, I think Hugo has a way to automatically generate a table of contents, but it doesn’t seem to know what [toc] means. So let’s just look up the template and config info.
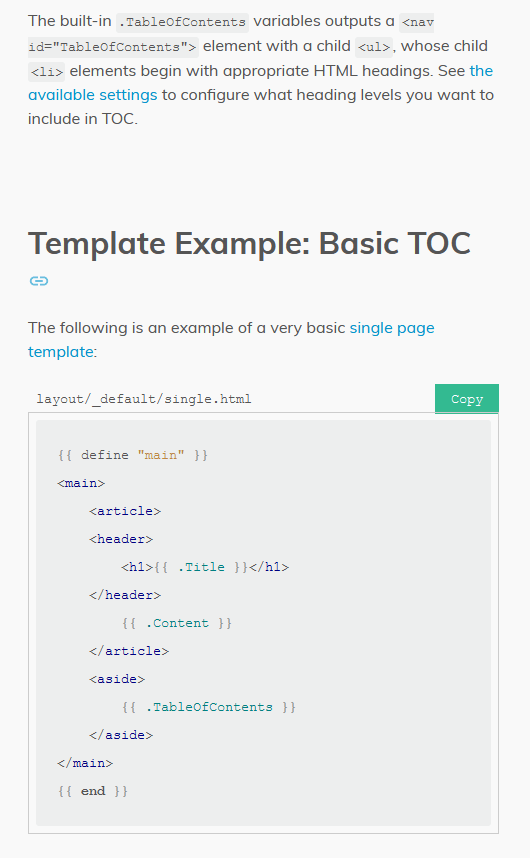
# This looks pretty nice, but the “content” of this page doesn’t really look like one single cohesive thing. It looks like two things. The little designer in my brain objects to this visual clutter.
# Maybe I should just fill it with a background?
# Yeah, I guess this works.
#Updates page - Manually loading an RSS feed
# So how do I re-create the behavior of my old website’s “updates” page? It used a fairly elaborate system of loading the XML file of an RSS feed, extracting the last 6 things in it, grouping them together by project, sorting the projects chronologically, and generating collapsers for them. I only recently started learning Hugo. I don’t know if I’m feeling up to attempting all that using Hugo’s templates. It could theoretically be done, I dust don’t wanna.
# Actually, do I even want collapsers? I mostly only used them because everything was stacked on top of each other on the old site and I didn’t want to bury the “recent projects” too far down at the bottom of a long page.
# Besides, the RSS feeds for each individual project on the new site already look really nice and compact. Maybe I should just re-use that design? Like some kind of “cohesive design” or something.
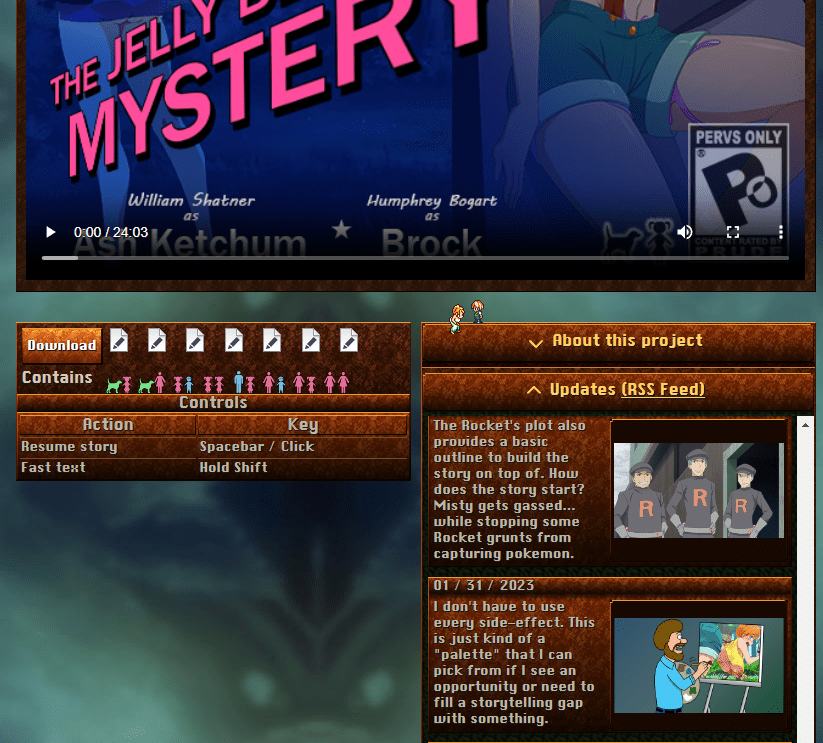
# I could do this with just one line of HTML. Just use an iframe to display the XML file. I already have a magic XSL file that makes the web browser transform the XML into HTML when you view it.
#
<iframe src="updates.xml"></iframe>
# But… this would display all the updates backwards, from future to past. That’s actually what you want for feed readers, but when you’re reading text on a page you expect time to move forwards from the past to the future. Like everything else.
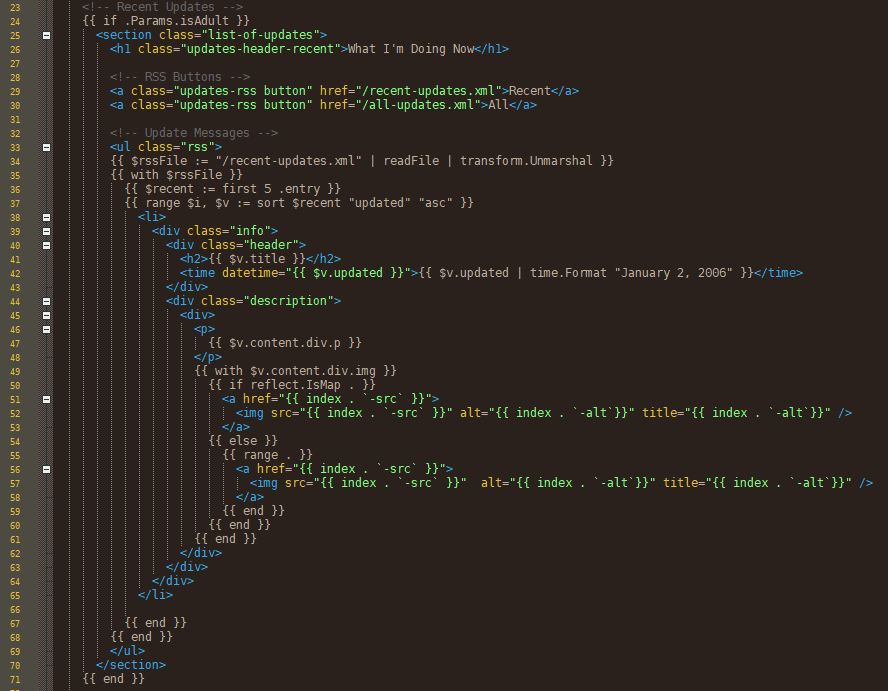
# So let’s load the file, trim it to the 5 most recent things. And then sort them in order so the newest one is at the bottom. Time to learn some more Hugo commands, like:
- readFile - to load a text file
- Unmarshal - to turn XML into data for Hugo
- first - to grab the first 5 things
- sort - to arrange things by date
- … and range - to loop through things (I’ve been using this a lot)
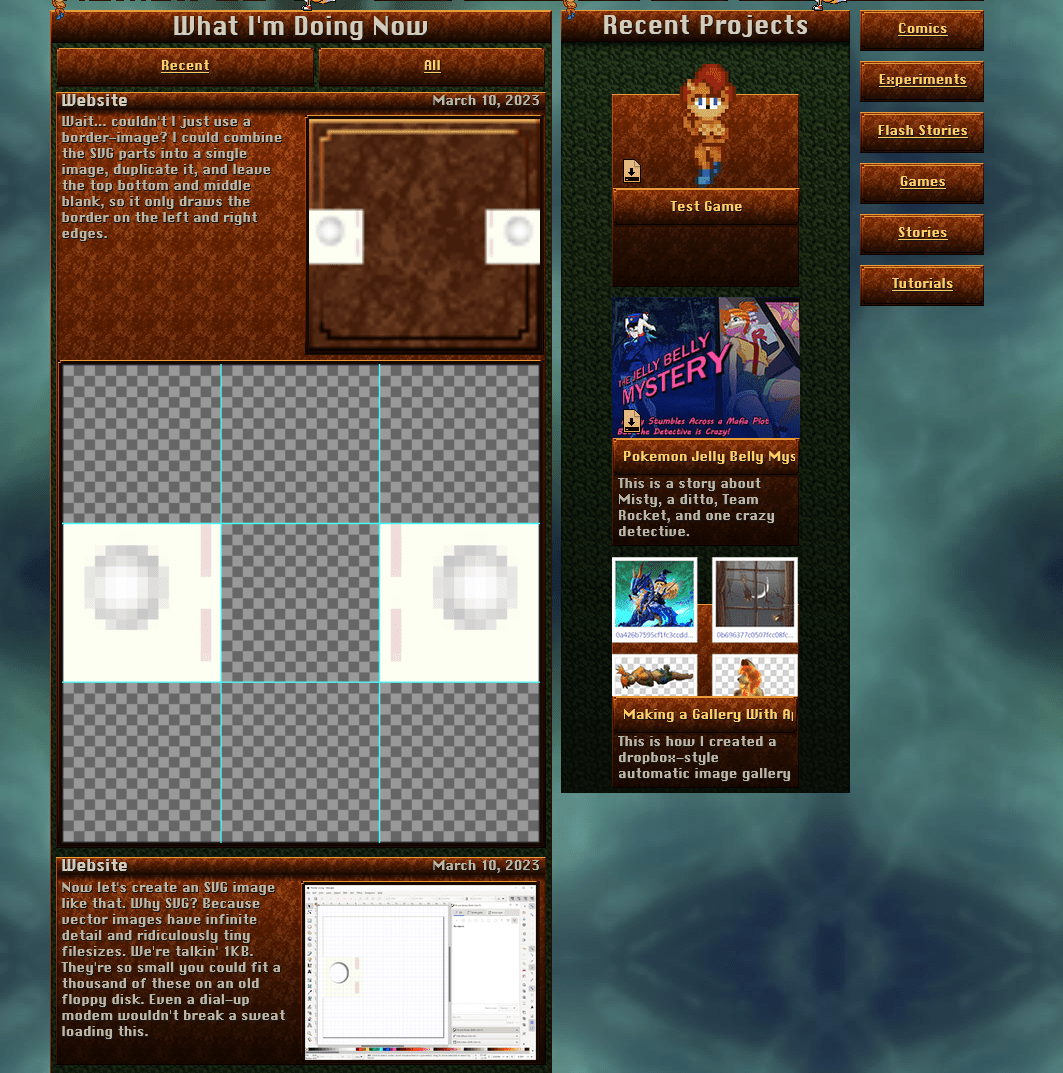
# … and the result uses the same CSS as the update feeds in the project pages.
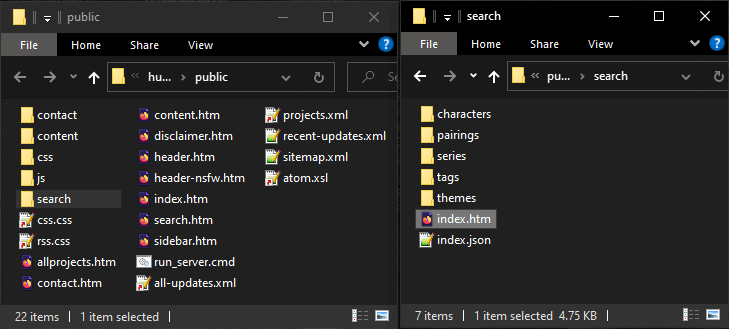
#Putting taxonomies into a “search” folder.
# I suspect most people only search for one thing at a time. Hugo can pre-generate those results, and I can make them thumbnail galleries. So you could have 75% of the benefits of a search engine without JavaScript. Besides I was using this phone friendly menu where you just tap on the buttons for each keyword. There’s no reason those “buttons” can’t just link directly to these pre-generated pages.
# Of course, I still plan to add JavaScript search later as an optional extra for people who have JavaScript enabled. PageFind looks promising. Or I could just adapt my old website’s search code.
#Making shortcodes XML “compatible”
# I’ve been reading Cory Doctrow’s blog about how he’s been writing online for over 20 years and the workflow he uses. He’s not particularly technical, but he uses XML for everything. There’s something appealing about making content in a format that is that compatible.
# I also read a fascinating article about the history of HTML, the need for reusable but complex things in HTML, and how XML tools had already solved these problems for people and companies who create and publish documentation in multiple formats. It got me thinking about making content that’s not just compatible, but portable, widgets and all. How do I make other things understand my website’s pages?
# Tons of things can read XML. My new website uses MarkDown, which Hugo converts into HTML, which is basically XML. So I’m kind of on the right track… except for those damn shortcodes! Nothing is going to understand those!
# Hmm… it looks like Hugo let’s me write them like this.

# This might technically qualify as valid XML. Sure the curly braces would be treated like the rest of the text in the document and look ugly as hell for no apparent reason, but it won’t break other programs in the future.
#Converting XML tags into Hugo shortcodes.
# I have a crazy idea. What if I manually load EVERY file and use text-replacement to turn XML into shortcodes. That way the MarkDown can use normal XML that other programs might be able to use in the future. Why XML? Because MarkDown already turns into XML when you convert it, because HTML is XML.
#
MarkDown + XML = HTML + XML = XML
# And a lot of programs can read that.
# I love Hugo, but how do I know something better might not come along 10 years later? I might want to redesign my website again. The least I can do is make it easy for myself, by making its data as compatible as possible.
#Comic image anchors
# You know how when you read a comic online you can just click the page to go to the next one? I love the brilliant elegance of that.
# Of course the whole point of using Markdown is that it makes it simple. You can just drag and drop all the pictures and you’re done.
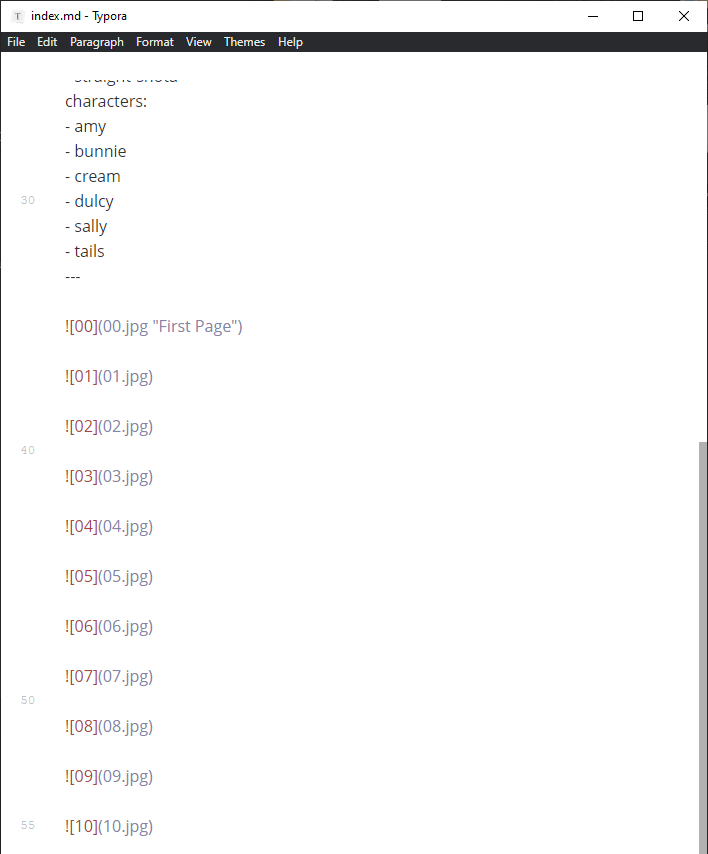
#
But since I have one file with all the pictures in it, I could use anchor links to click between them. But adding these in markdown would be a hassle, so should make Hugo do it for me automatically. I need to wrap all the images with <a href> links. Hugo can do this using Render Hooks. It’s like an override for its markdown parser so that instead of turning markdown images directly into <img> tags, it’ll use your custom template instead to create each one.
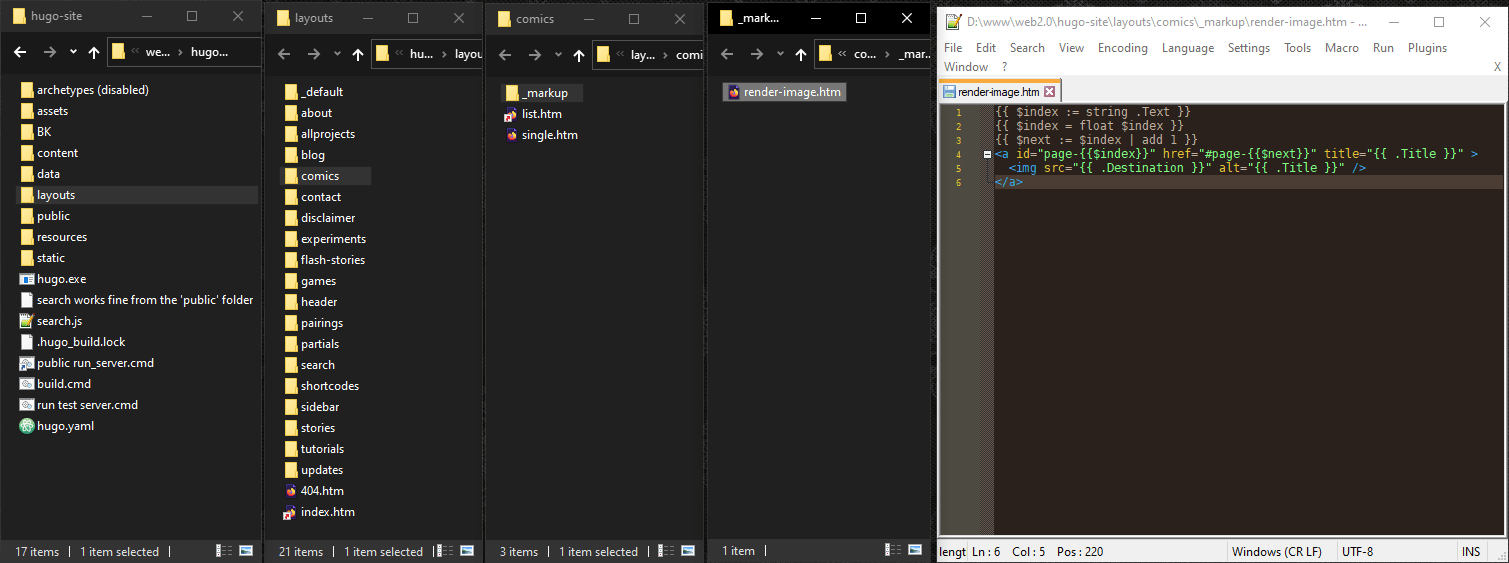
# Typora automatically adds the filename as the alt text. I use numbers for all the comic pages, so if I can read this as a number and add 1 to it, I could link to the next page. So here’s how I did that.
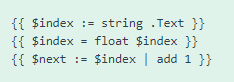
#
Since this file is a render hook template Hugo has already given me some variables about this picture.
First I read .Text to get the “alt” text of this picture and turn it into a “string” (which is just how programmers say the word “text”)
#
Then I use float to turn this into a “floating point” number, because Hugo struggles with “integer” numbers for some reason.
#
Then I put an | add 1 at the end of the variable to add one to it. So now I can give this picture an id with the old value, and give its link an href using the increased value. That way every picture has a number and links to the next number.
#Filtering adult content for the “decoy” site?
# This could be a royal pain. I don’t want to generate 2 completely separate but similar-looking sites. I mean I do but I don’t want to program it. The decoy’s purpose is mostly to make the default website look safe-for-work to fool the web host. It’s meant to be ignored by everyone else whose here for the real smut, so I don’t want to waste too much effort on it. Sure it respectfully offers a “clean” version of the site for people who are not into porn. But let’s be honest, that’s basically nobody.
#
Maybe I can make CSS do some of the work. Add a SFW or NSFW class to the page’s <body> tag. Now any adult thumbnails will be invisible.
# But this leaves suspicious ugly gaps in the galleries.
# Add an isAdult flag to projects and then tell Hugo to include or skip them based on whether this gallery’s page has a isAdult flag?
# Do I really want to do this for every section of the website? What if I just leave out the sidebar on the clean version? That’s basically the mobile phone experience anyway. It was always optional.
Navigation checks for "isAdult" page flag.
Galleries skip NSFW projects.
Hide the website's update feed.
Uh oh! Clean projects can navigate to the "clean" site and confuse people.
Idea: My old site had the option to view projects as stand-alone pages with no navigation.
Solution: "clean" projects have no navigation at all. Just stand-alone pages.
#imgSource
# I love recommending awesome artists. But in order to make it look nice it takes a whole bunch of HTML tags. On my old website I used to just copy and pasting them on every single page, it would be better if I could just use a simple placeholder instead and have Hugo replace it with my artist-recommendation HTML. That would make it easy to change in the future.
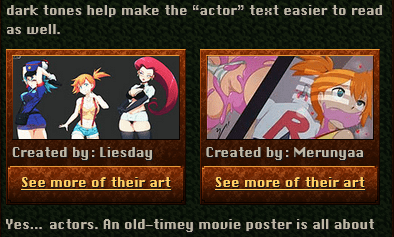
# Fortunately, Hugo has something called shortcodes which can do this exact thing. I can just type this as a placeholder.

#
… and Hugo will replace it with all that HTML junk up there.
Here’s the shortcode template that does that.

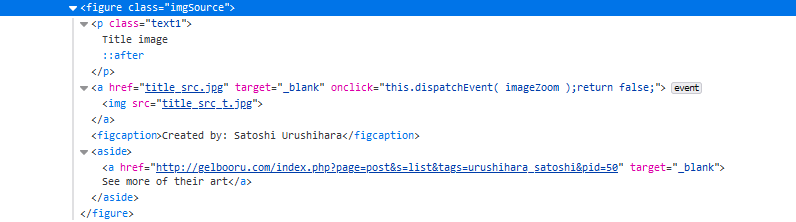
#I figured out how to use XML tags as shortcodes
# Hugo’s shortcodes are handy. You can put a single placeholder in your markdown, and Hugo will replace it with whatever HTML you want, no matter how complex. For example, I want a custom HTML widget specifically for recommending artists. The result looks like this.

# But its shortcode looks like this.

# The problem is that only Hugo understands this! What if I want to use some other program in the future to edit my website? But here’s the thing… it’s so close to being a normal XML tag. Which tons of programs can read.
#Why??
# But why do I want XML in my Markdown files!? Because I want to make my website forward-compatible by making it readable by other programs besides Hugo. If you put an HTML tag into a markdown file, most other programs simply pass it through into the resulting HTML file unchanged. The same thing happens with custom XML tags. And since HTML is just an XML file, other programs will be able to read it and interpret these custom XML tags any way they want to.
# But for now I want Hugo to treat these tags like shortcodes. Basically I want to be able to write this in my Markdown, and still have Hugo convert it into the custom HTML widget above.
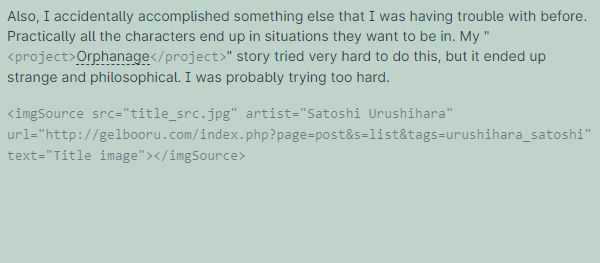
#How?!
#
The trick is to perform a text-replacement, which is totally a thing that Hugo can do. Replace <tag> with  . But to do this, you have to load the file manually, modify the text, and then send that to Hugo’s markdown parser.
. But to do this, you have to load the file manually, modify the text, and then send that to Hugo’s markdown parser.
- First I tell Hugo to manually load the raw text of a file, and store its contents in a string variable.

- I also remove any front-matter at the beginning using a regular expression, just in case.

- Then I use text-replacement to add curly braces around each of my custom tags to turn them into “shortcodes” that Hugo can understand.

- Then I send this to Hugo’s markdown renderer to convert it into HTML.

- And then spit that out onto the page.

#Search
# PageFind looks cool, but I can’t get it working.

# Let’s try the Fuze.js tutorial.
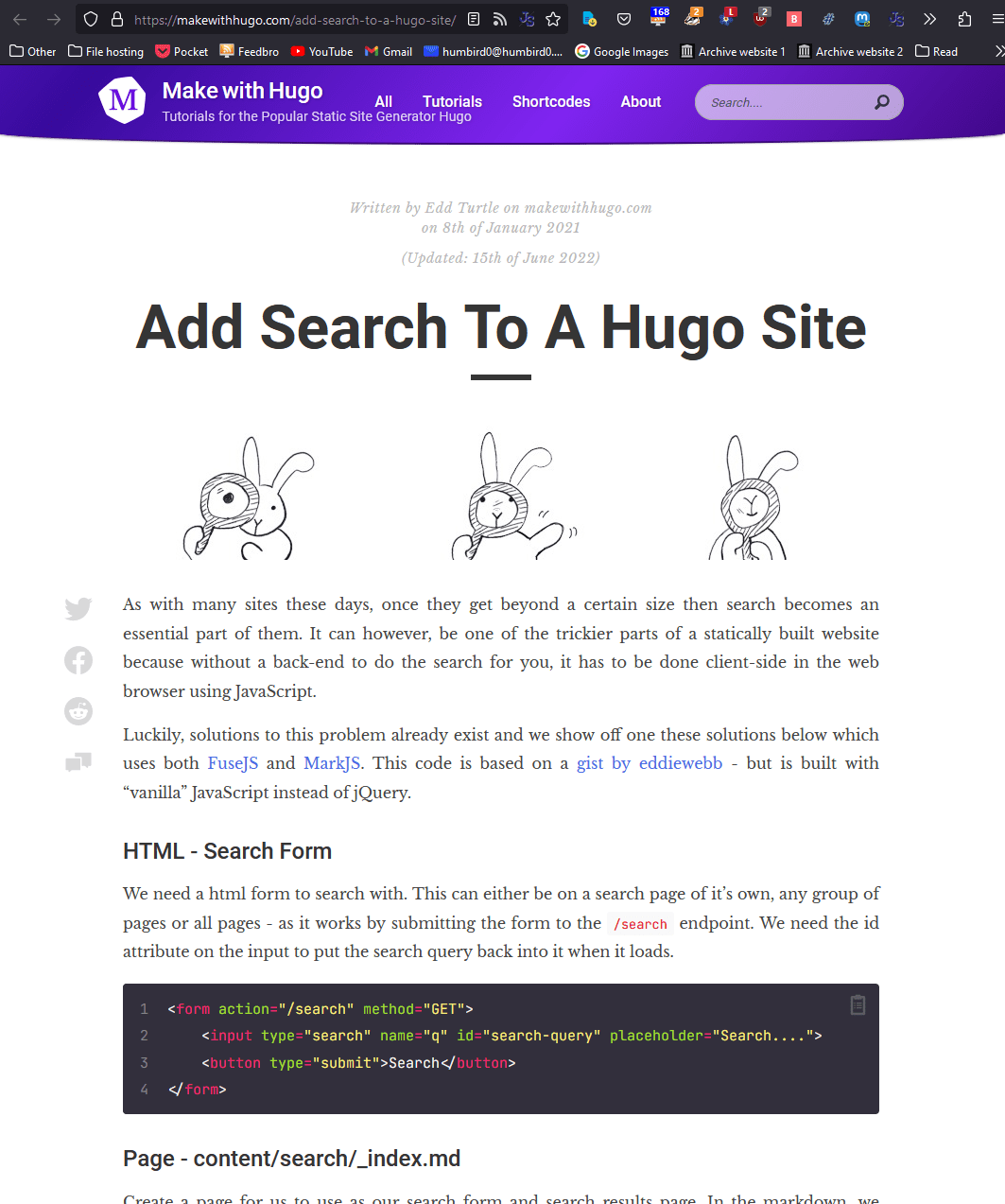
# Okay, it’s actually working… for the most part. The relevant results are at the top, but… it still includes everything else in the results for some reason. There’s probably a setting for that. I’ll figure it out later.
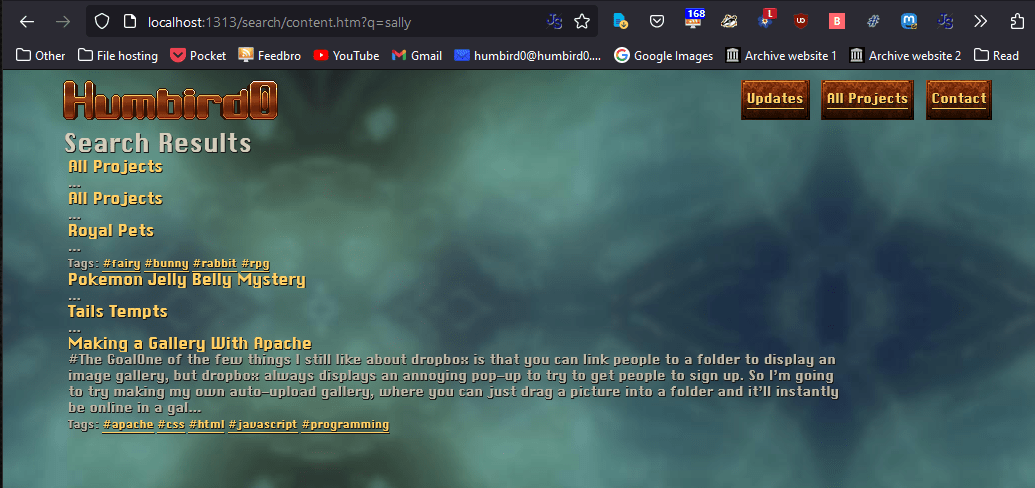
# I kind of wish I could move the search index’s JSON file though. To me it makes more sense to store it inside my “search” folder. Is there a way to move it?
#
Okay, it took a ton of figuring out, but here’s how I managed to move one file from here /index.json to here /search/index.json
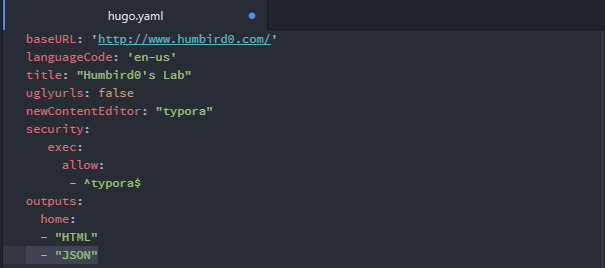
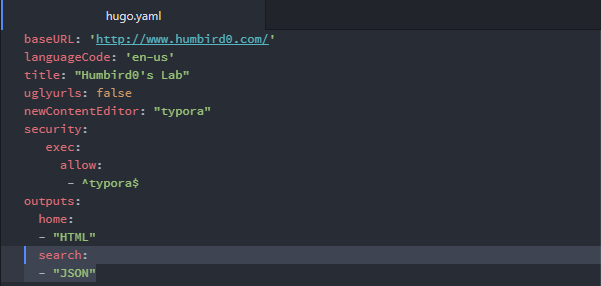
#Step 1: Change the “url” path
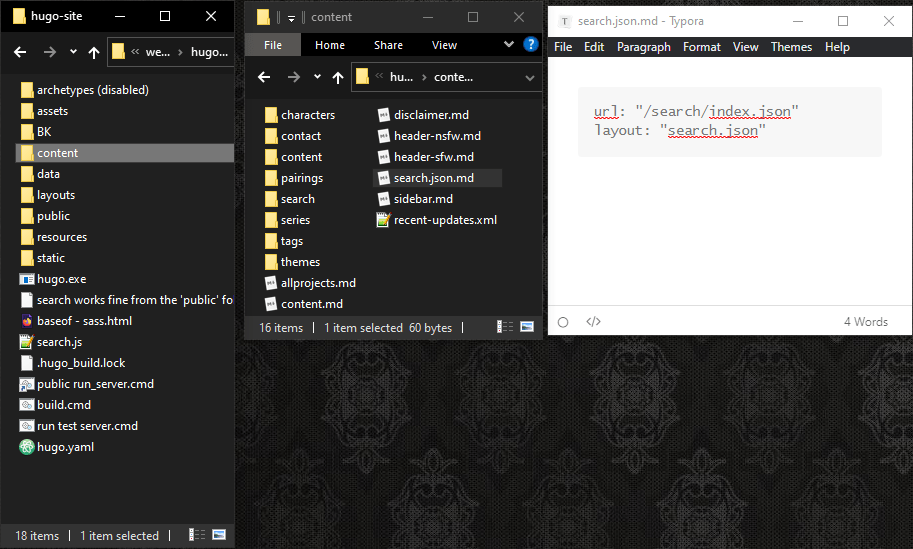
#Step 2: Rename the template
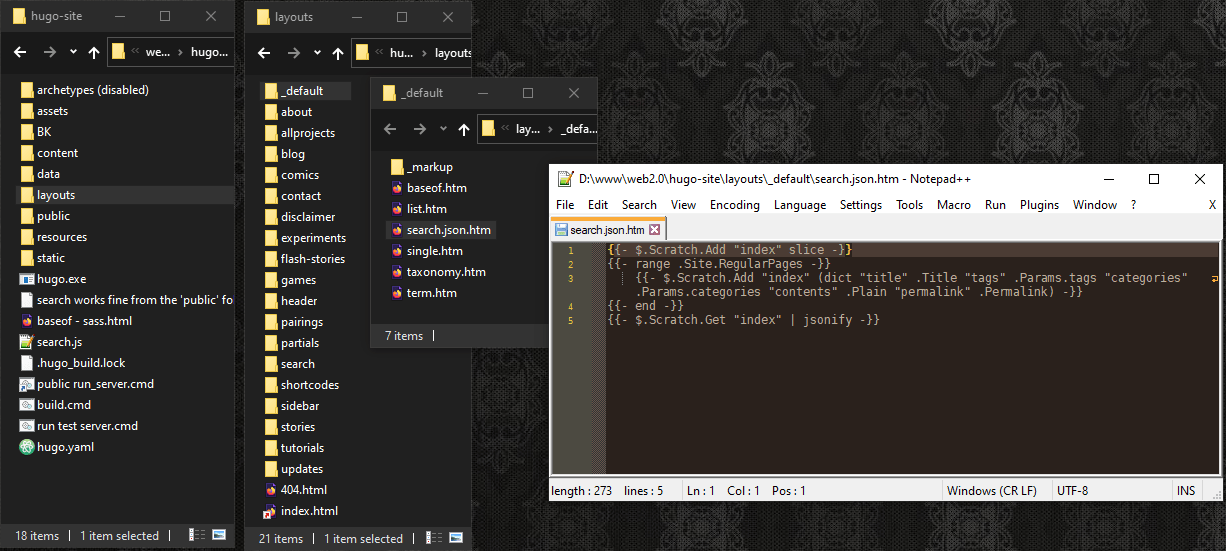
#Step 3: Add “search” to the website’s “config” file
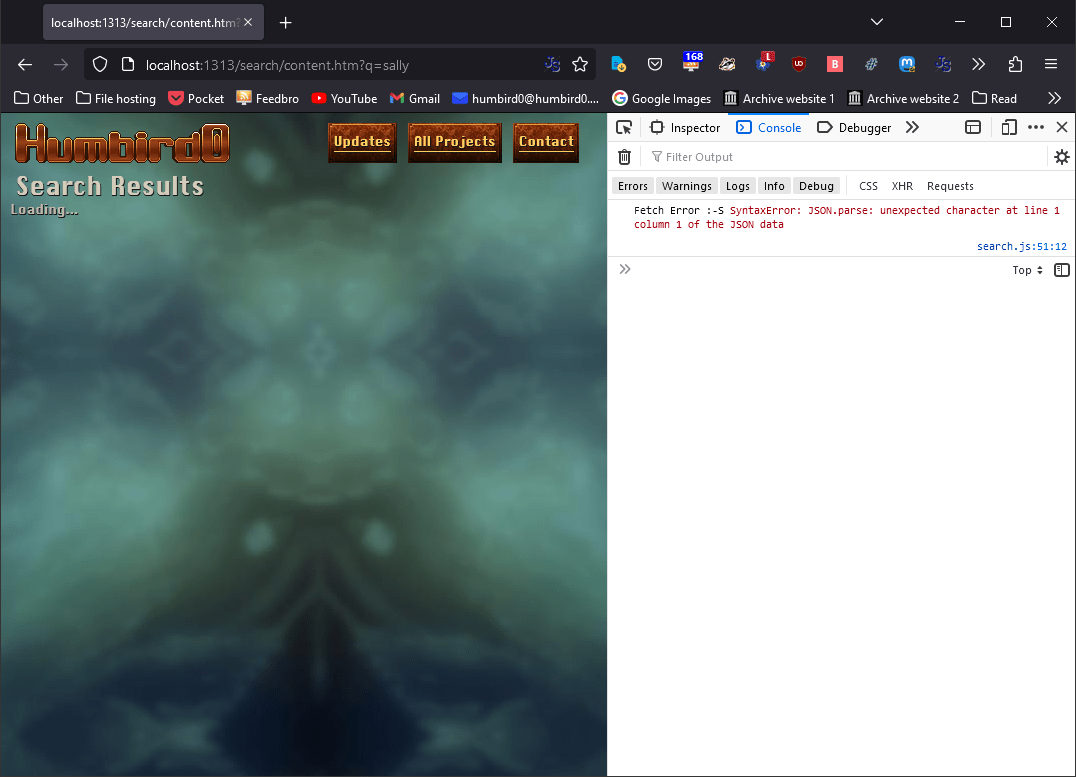
#Eek, a bug!
# There’s just onnnne little problem. Now the search is broken in Hugo’s test server…
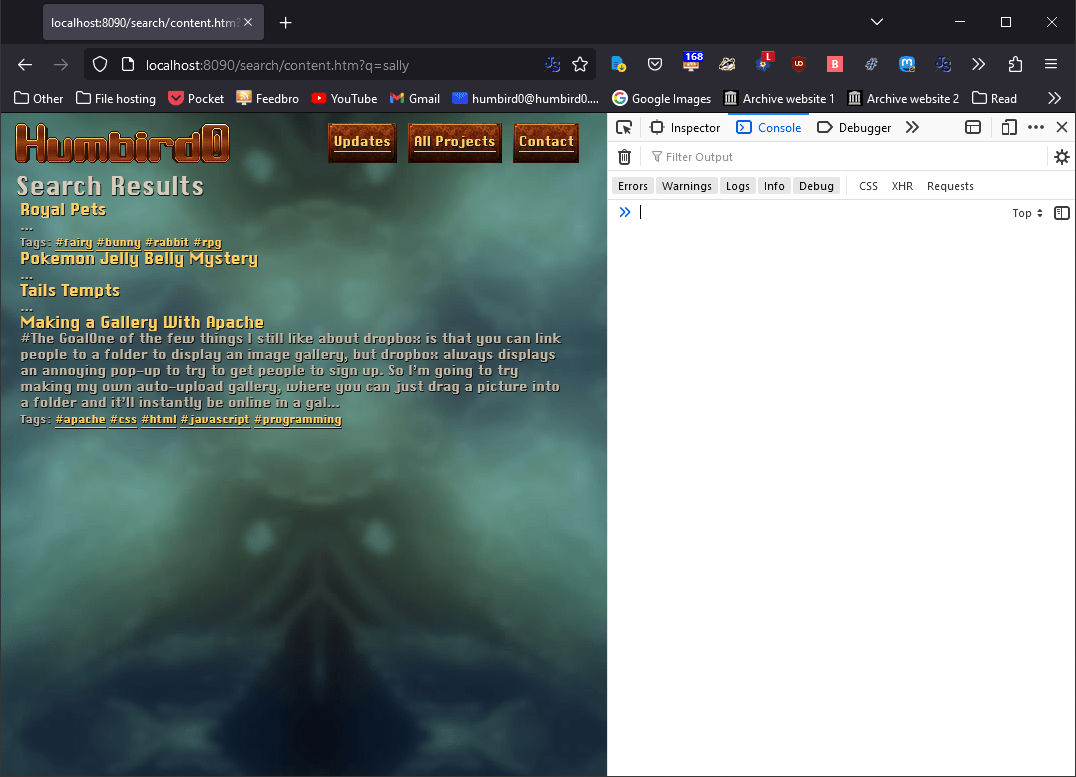
# … but does work if I generate HTML files on the disk and run it from that “public” folder.
#
The error only happens when the search.json.md file exists. You know, then one that I controls where the JSON file goes. It doesn’t even matter if the JSON file actually gets moved. Even if I tell Hugo to put the file in its original location the error still happens! Hugo’s server just doesn’t like this MD file specifically.
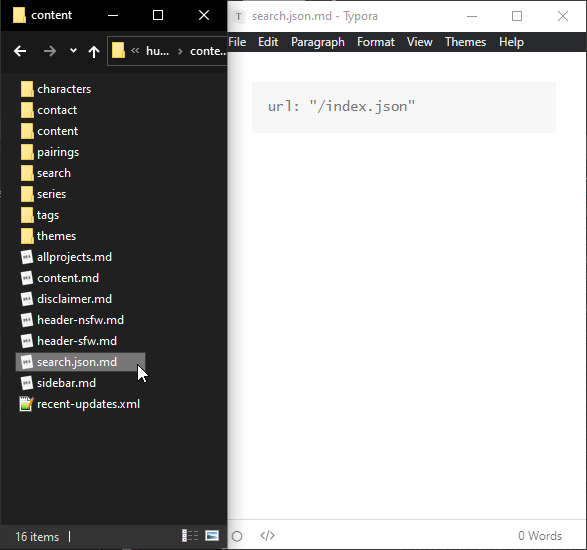
# Internally, Hugo seems to be getting confused and putting HTML into the simulated JSON file, but not in the real JSON file.
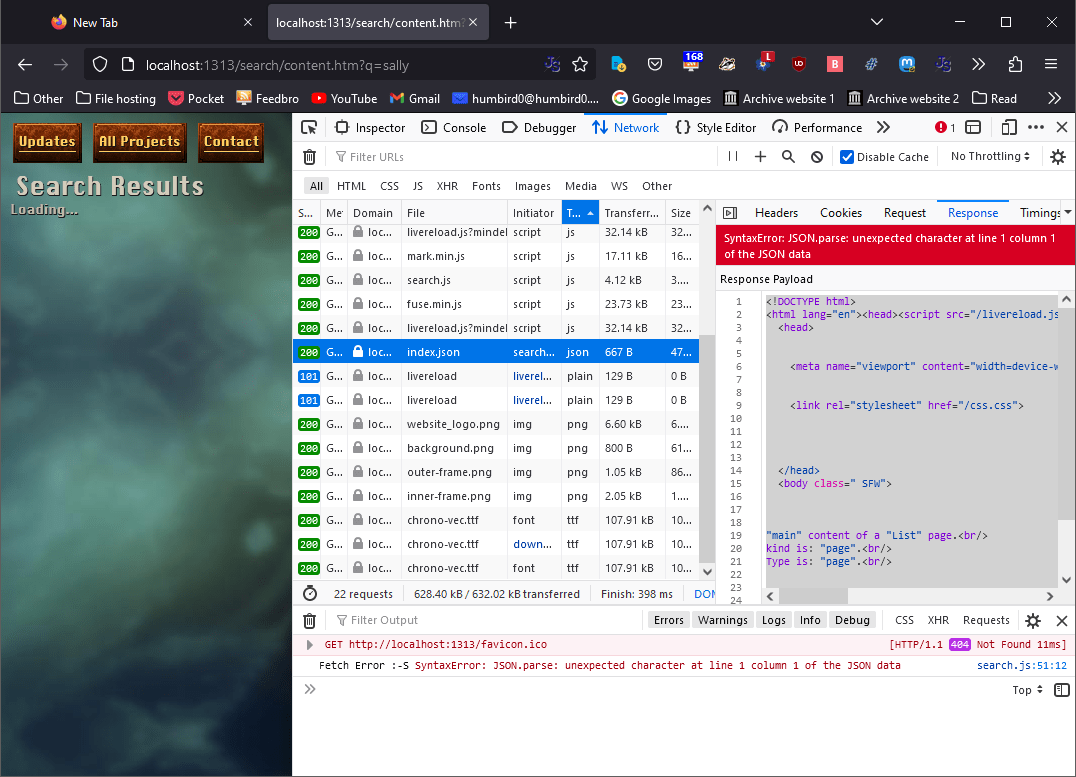
#
Hugo’s server is also complaining about something called a “duplicate menu entry” … whatever that means. But it’s talking about the file header-sfw.md which is used for my header iframe, so I doubt that has anything to do with this search glitch.
# … Maybe it’s because I have 2 header files? One for the clean decoy website, and one for the NSFW version, and they both define something called “menu?” Maybe Hugo’s only warning me in case I did this by accident. It’s not an accident. I gave them both menus on purpose, and they’re working perfectly.
# Anyway… it doesn’t really matter. The “public” folder is the only part that matters, since that’s what will actually get uploaded to the internet. So as long as that works, then the actual website will work.
#Fumbling around for things… in style!
# Now let’s style this to look like my other galleries.
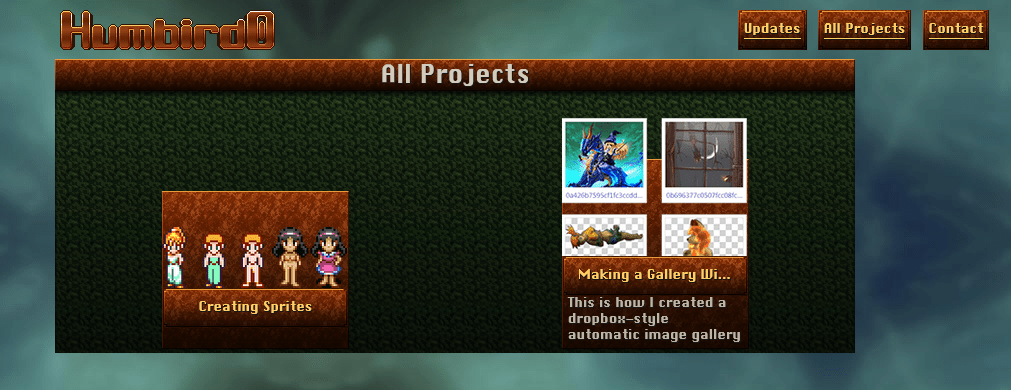
# It looks like they’re using proper vanilla HTML5 templates, which doesn’t have logic like Hugo or Handlebars.js, but I guess that’s fine. The WHATWG web standards probably expect people to use JavaScript for all the logic.
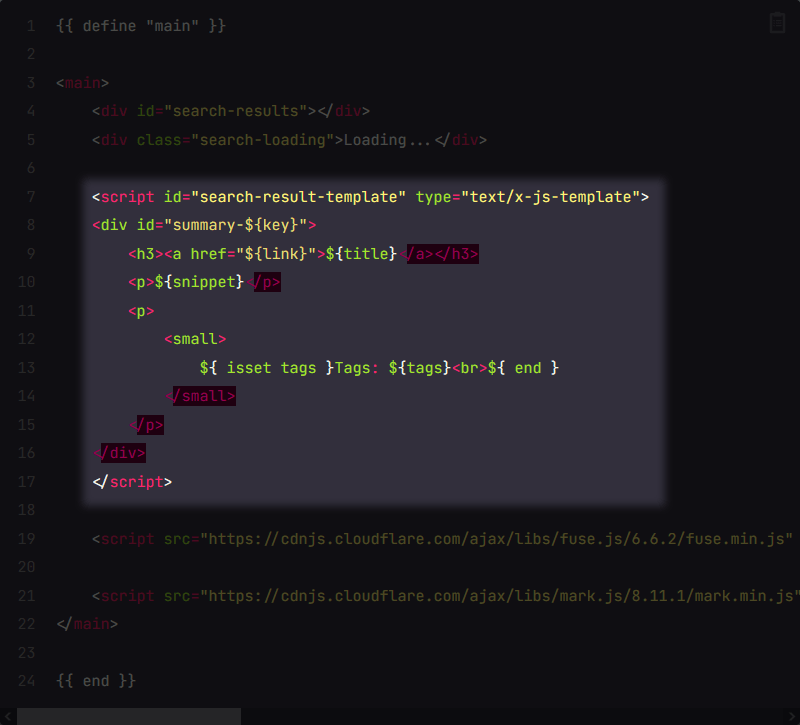
# Okay, maybe it does let you use a little bit of logic.
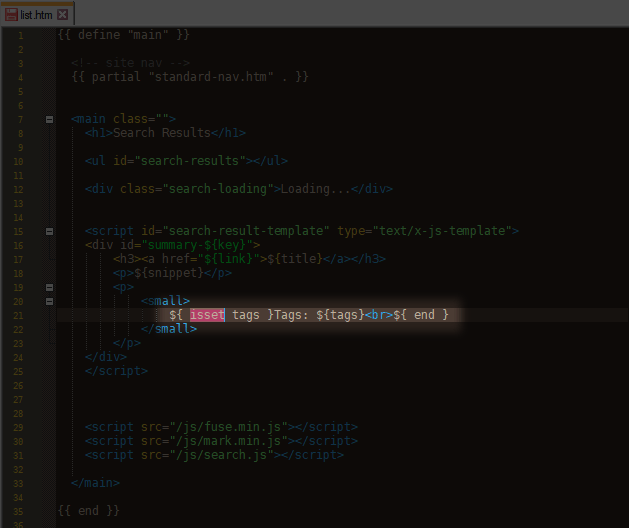
#
But for some reason I can’t seem to find anything about this isset command on Google. Oh I see… it’s a custom thing added by the example search code.
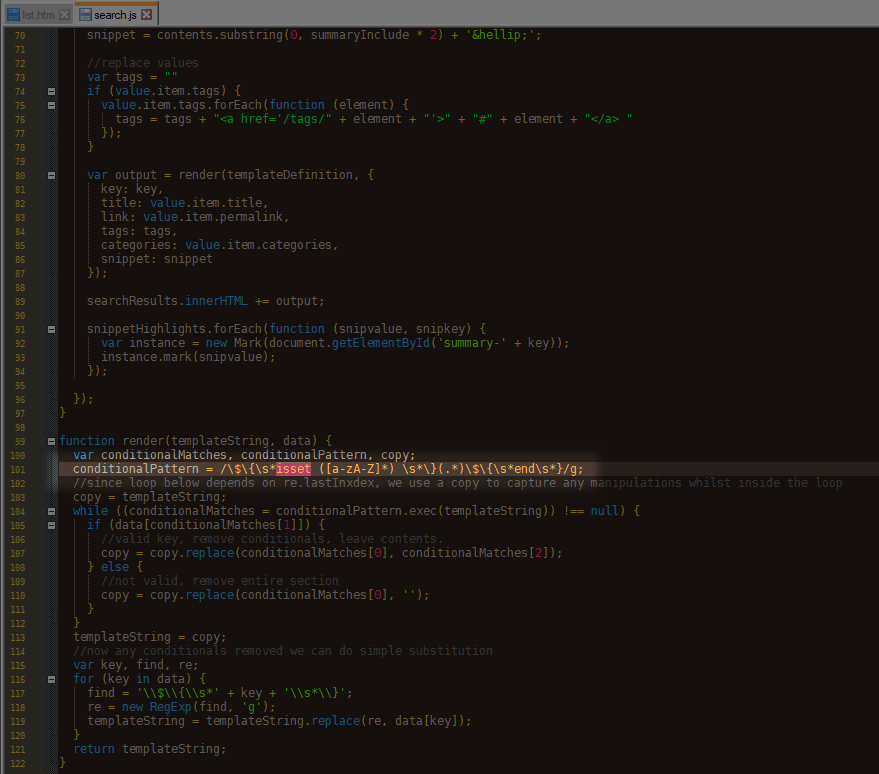
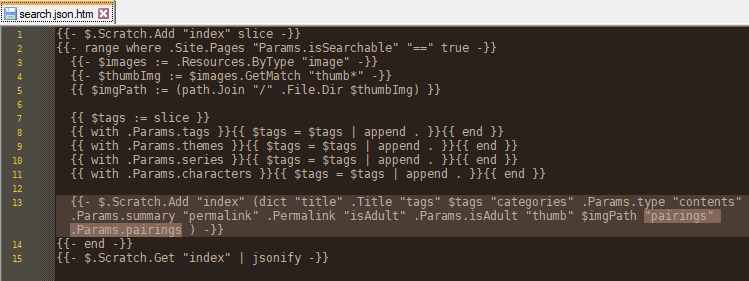
# Anyway, I’ll just make it easy for myself and simplify my search result’s thumbnail template to leave out the things that need logic, like the download icons.
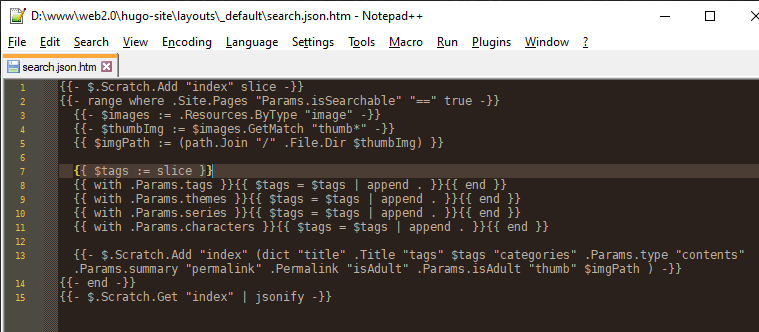
# Let’s add all the other keyword lists to the search’s “tag” list. I want the search engine to check them all.
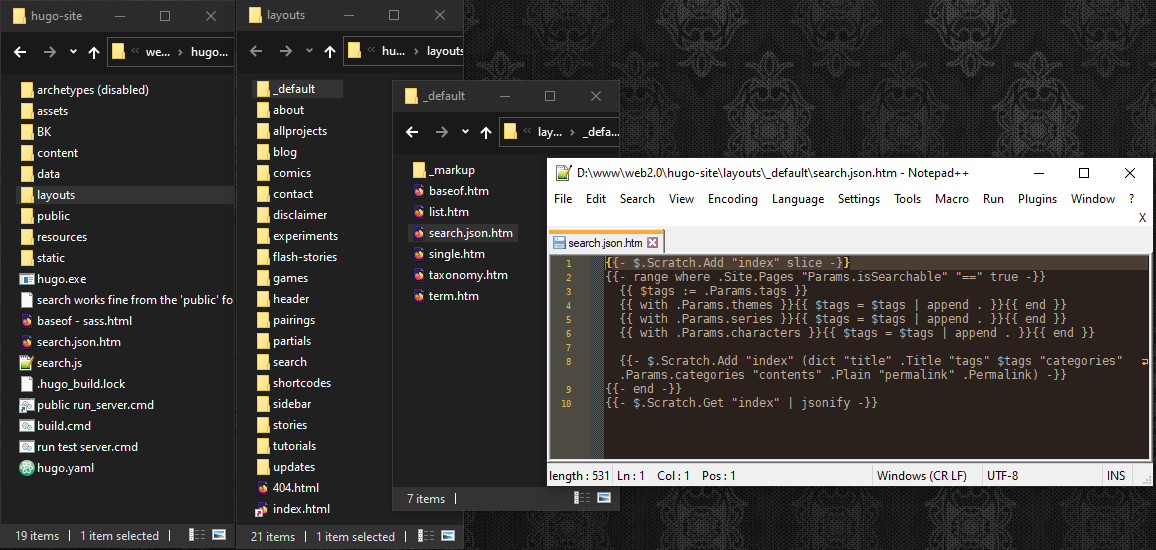
# I normally store each project’s list of “characters”, “themes”, and “pairings” separately in case I want to display them in different ways, like the “pairing” labels in my thumbnails.
# Whoops. No thumbnails? Also, it’s jamming the entire text of each page into the short description text.
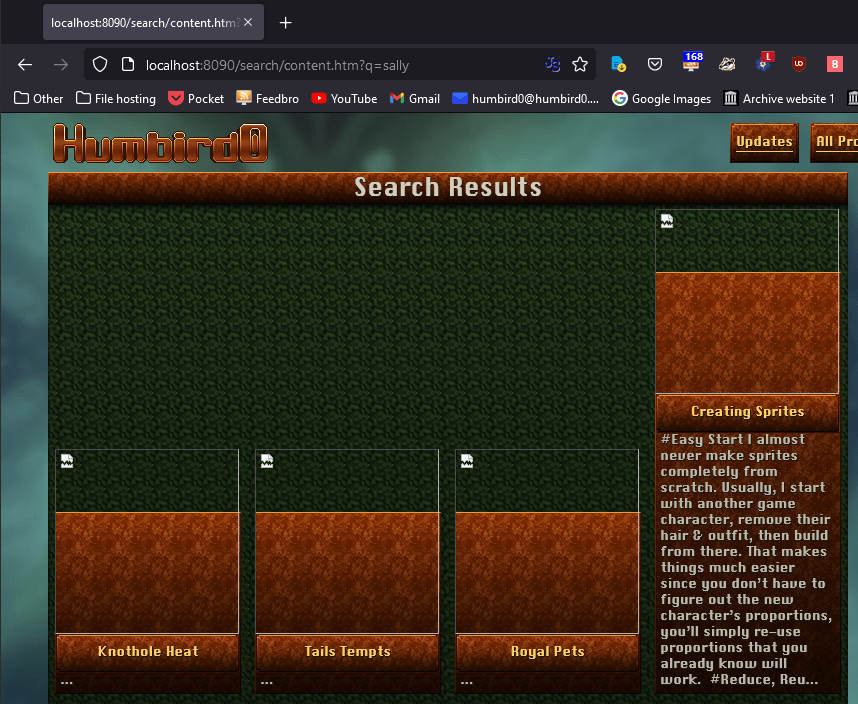
# Some projects use JPG files for their thumbnails, and some use PNG. I’ll just add each project’s thumbnail path to the search data so the vanilla JavaScript template can see it.
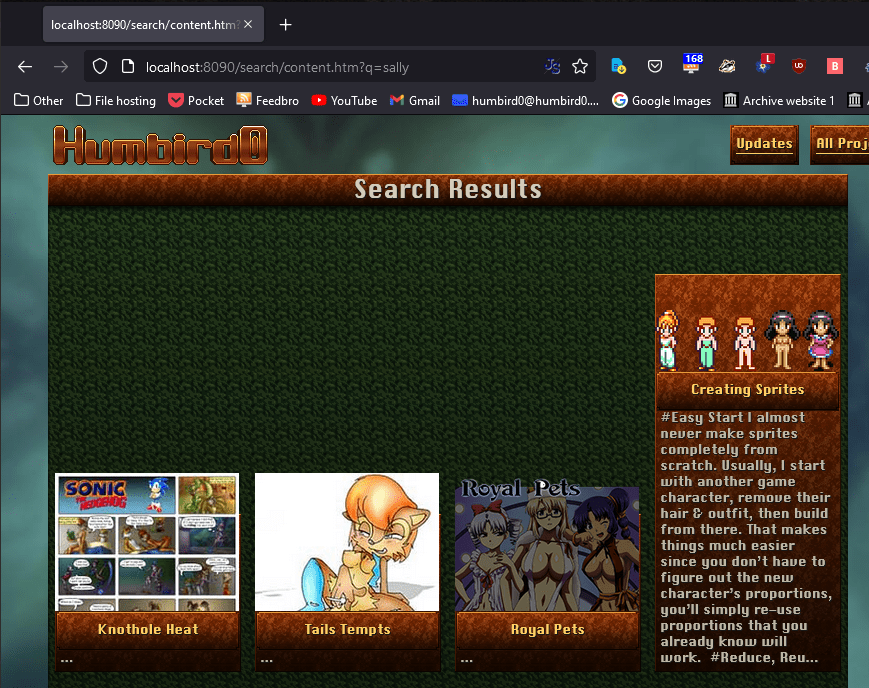
# Okay, let’s fix that wall of text.
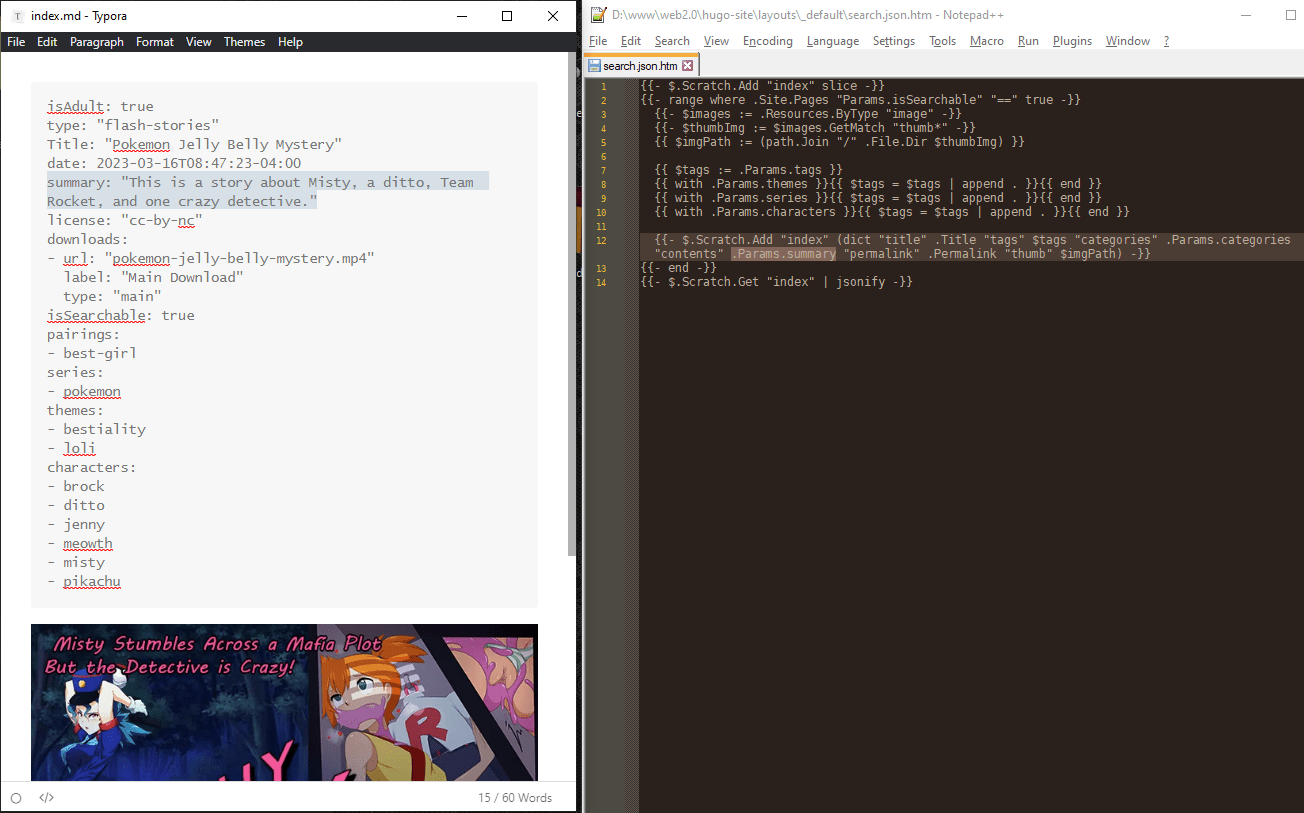
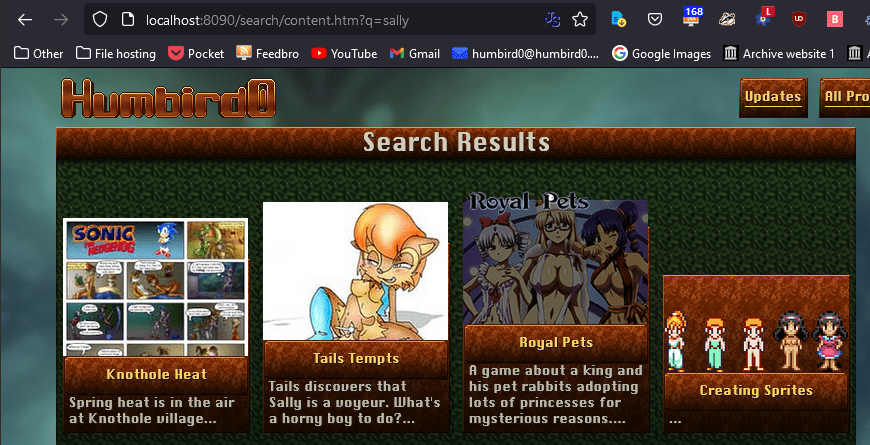
# Sure, this means this search engine won’t search the written contents of each page, but I don’t want to force people to download a gigantic JSON search-index file just to look for “lesbian pokemon”
# … and if you’re curious what’s actually inside a search-index. Here’s what the website’s pages look like to my search engine.
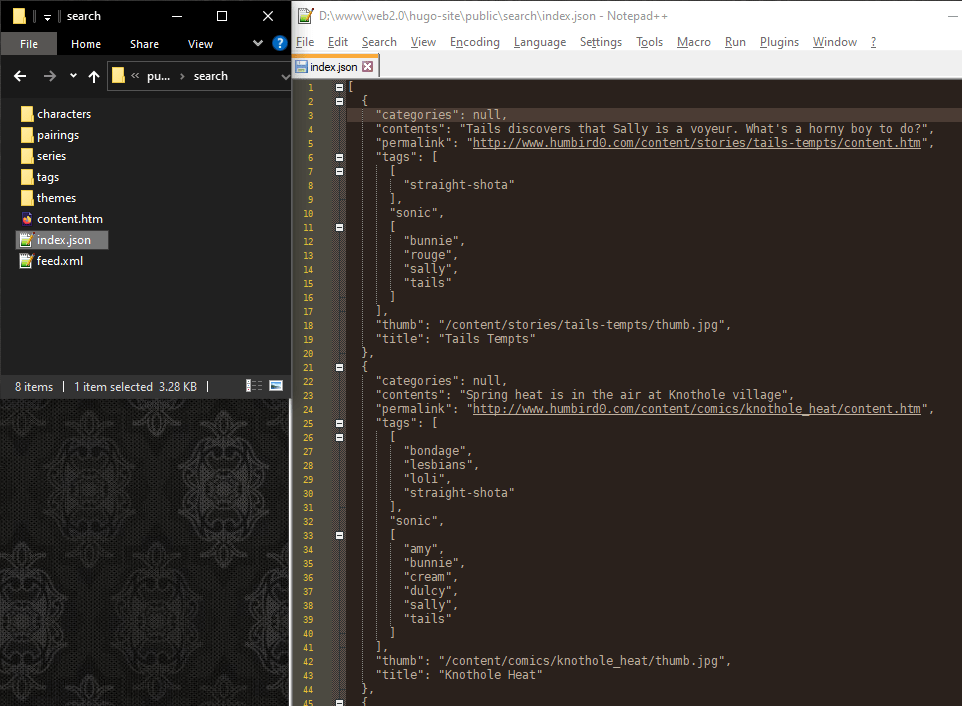
# Okay, I don’t want “null” to appear. It’s coming from my search JSON whenever anything is missing. Maybe I can create empty data and then append things to it?
# It looks like this is how you create an empty “array” in Hugo. This way, the worst that can happen is vanilla JavaScript template gets an empty list instead of “null” so nothing breaks or looks bad.
# I know I said I’d keep these thumbnails simpler, but I do want to at least have the “pairing” icons.
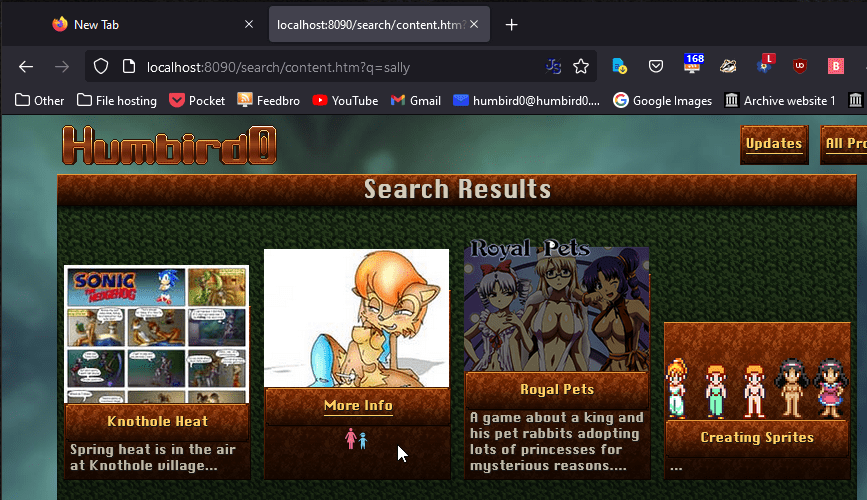
#Too much of a good thing
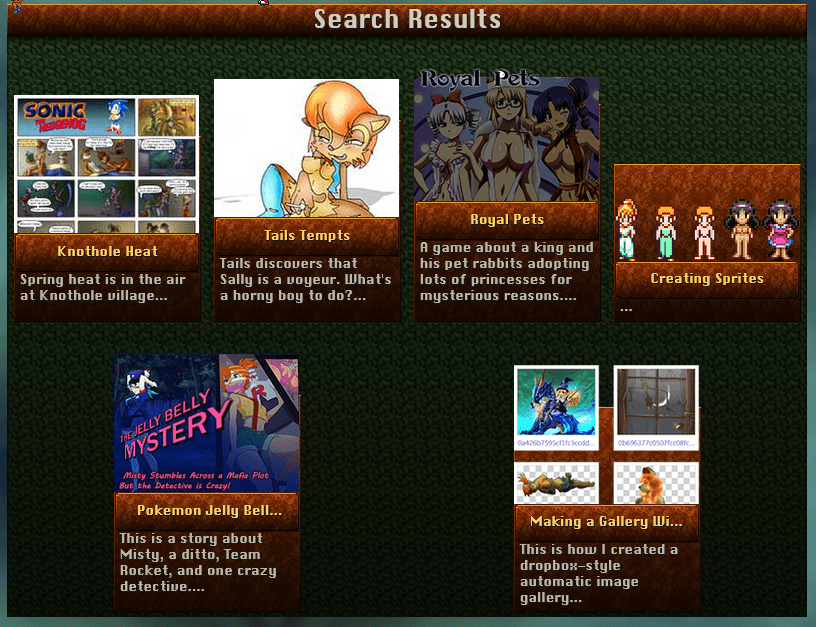
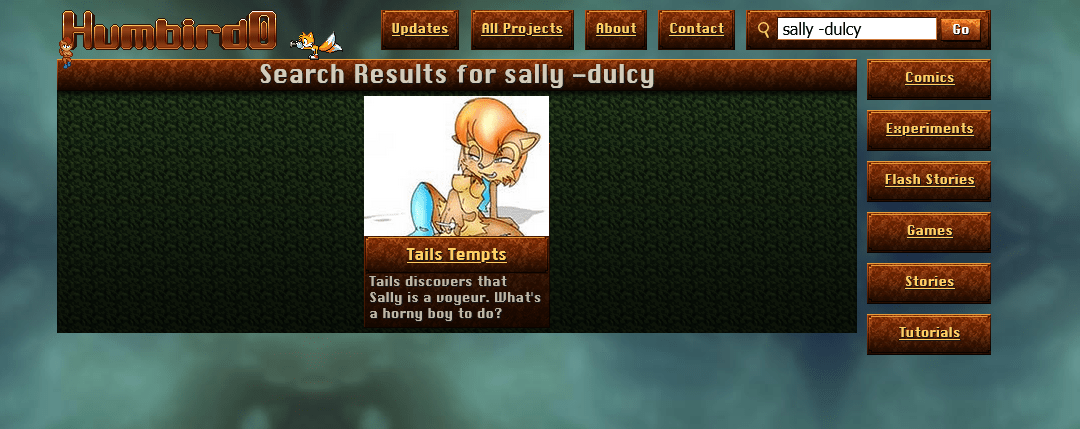
# There is one liiiittle problem… There are too many results. It’s mostly right, but those projects at the end don’t have anything to do with Sally Acorn.

# Let’s look at the fuse.js docs. Maybe there’s a setting to trim out unrelated stuff?
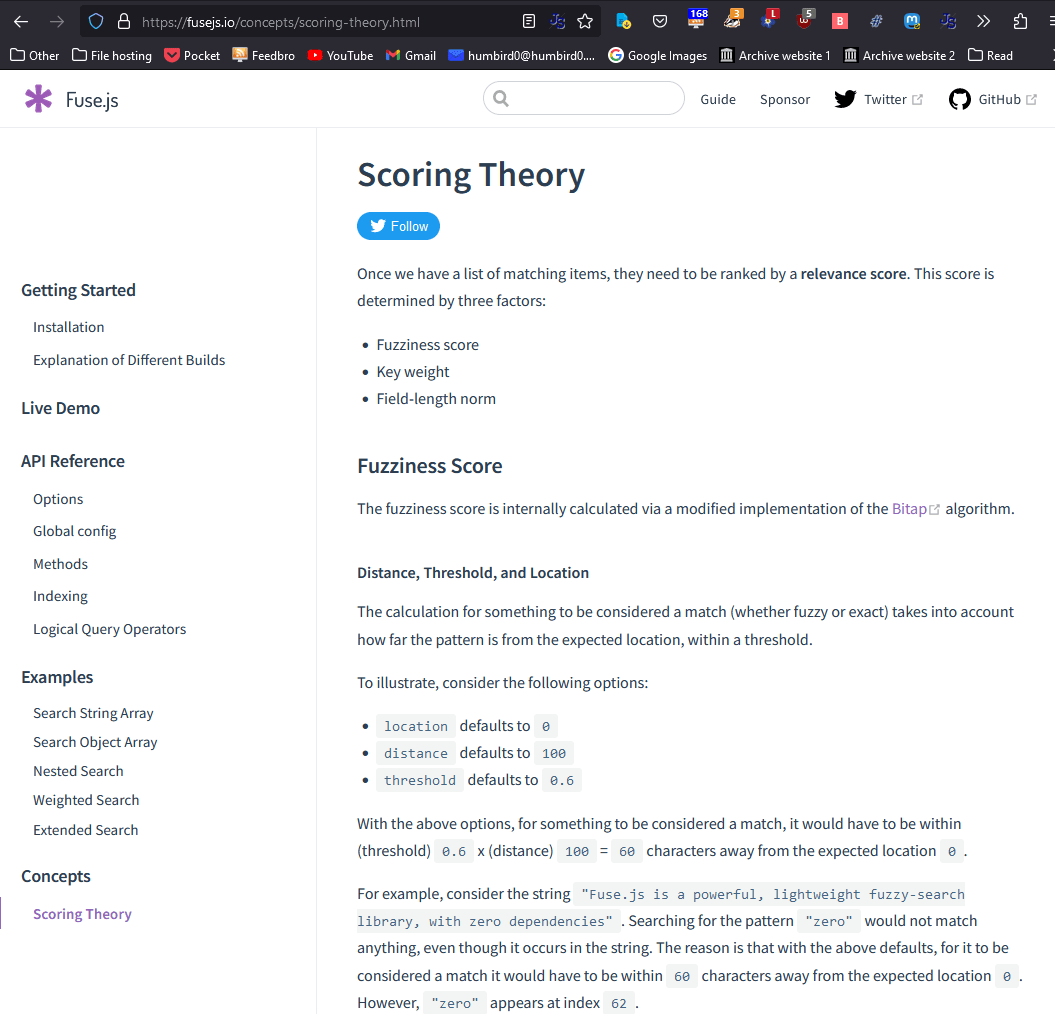
# Hmm… that “threshold” setting might be useful. Maybe I just have it set too sensitive? It says a match has to be “within” the threshold, so if I shrink that number that should make things more strict.
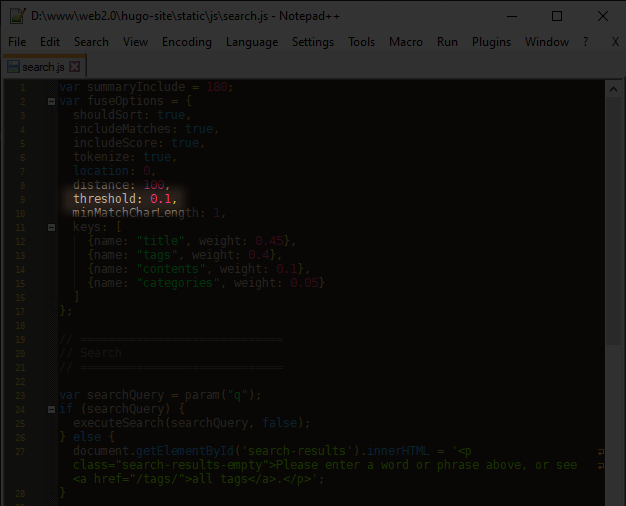
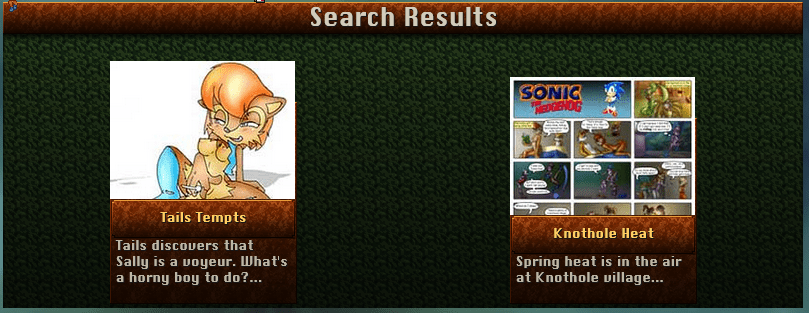
# Bingo!
#Using a different search engine
# Wait a minute… I can’t search for two words?!
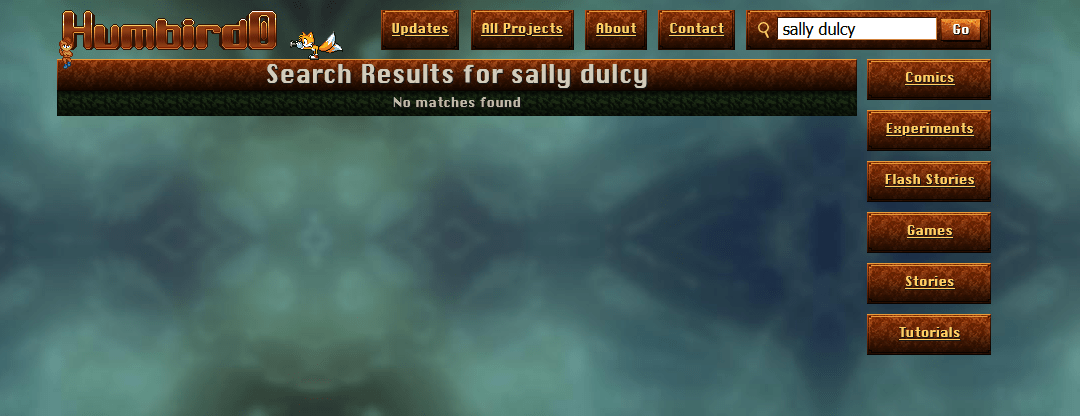
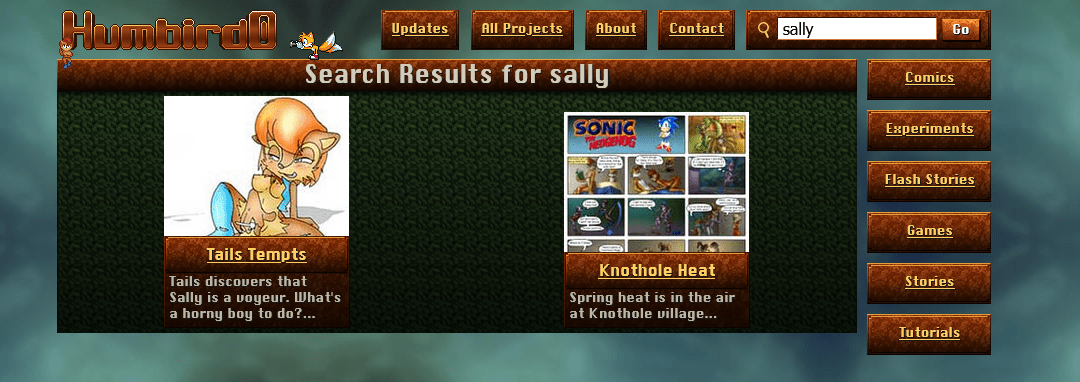
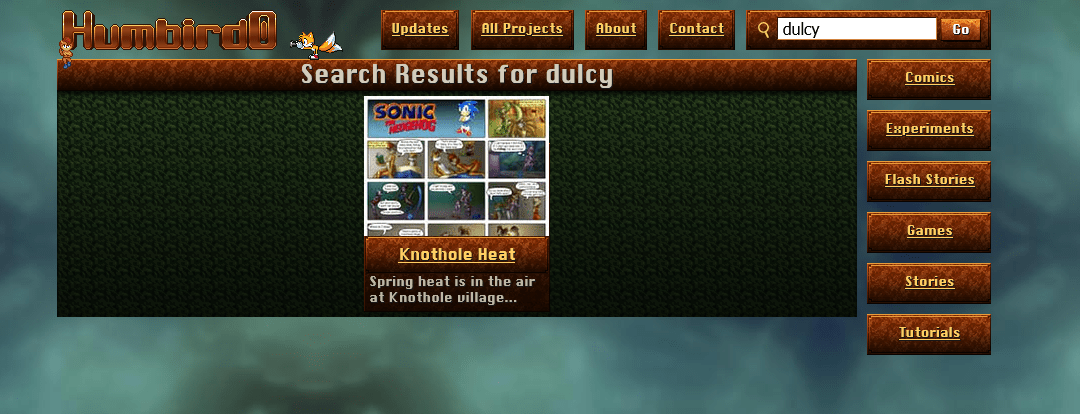
# … and I can’t -exclude things either?? That’s like the absolute bare-minimum feature of a decent search.
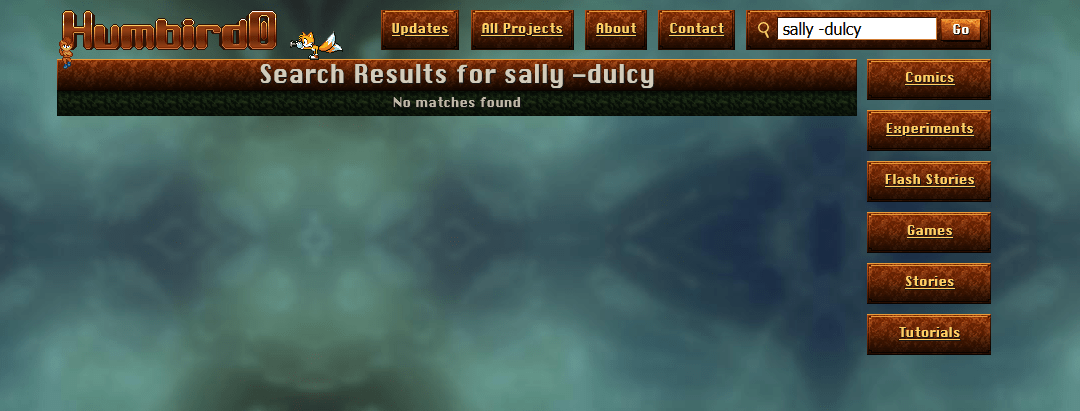
# Let’s check… okay the Fuse search engine only supports 2 things: “or” and “and.” Well that’s just pathetic.
# Let’s try the lunr search engine instead.
# Okay let’s modify my code to use this instead. Let’s see… the steps are:
- Load my search index JSON file
- Add each of its pages to the search engine
- Put the search box’s text into the search engine
- Display the output
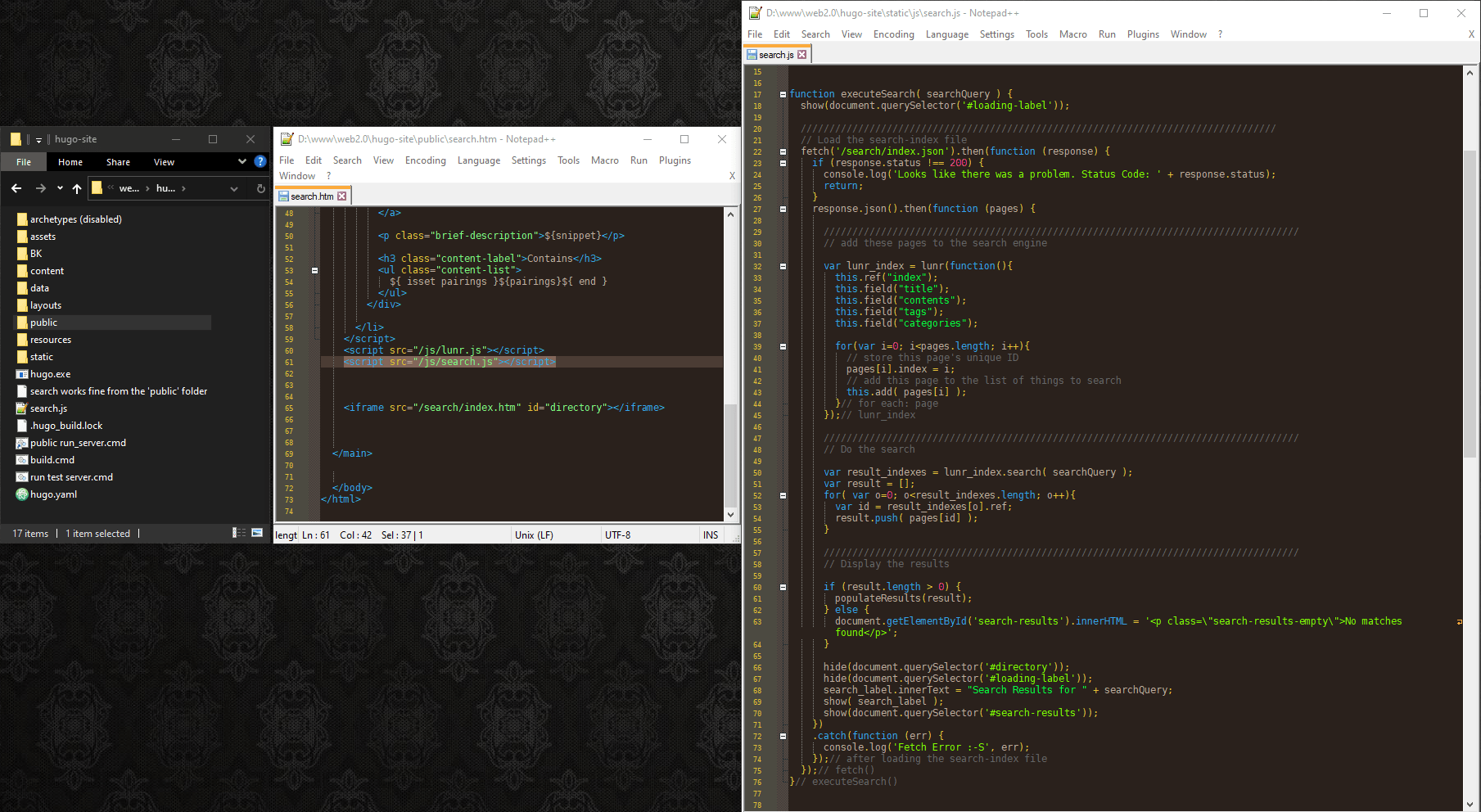
#
And it works!
The only tricky part is that Lunr gives you results as a list of index numbers, and you have to use those numbers to look up the pages in your JSON file to see what the actual results are. But that’s fine. It’s just one extra step.
#Moving the search page
# Okay, I have a bunch of stuff in the “search” folder so that people without JavaScript can just browse “taxonomy” pages, which are basically just pre-generated search results for every keyword, such as a list of all projects that have “Sally Acorn” in them, or a list of every project with “Lesbians.”
# For people using JavaScript I want “/search.htm” to generate actual search results in real-time by running some JavaScript in that page. The problem is that Hugo doesn’t like it when a file and a folder both use the same name. It’ll just skip creating the file.
# Hmm… but what if I name the markdown file something else, and just set its “url” to be “/search.htm”?
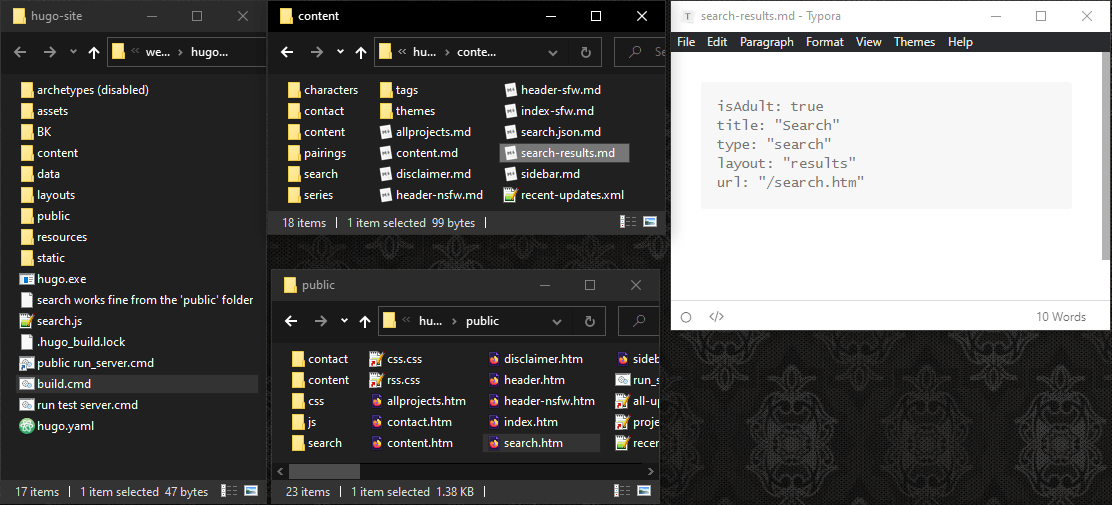
# Yeah, that worked… even if it’s a little unintuitive.
#Non-JavaScript Search
# I think there’s a way I can kinda-sorta provide people without JavaScript a way to search for things. Hugo can pre-generate search results for single words, and spit out pages for each result. Hugo calls these “taxonomies”
# https://gohugo.io/templates/taxonomy-templates/#example-list-all-site-tags
# https://gohugo.io/templates/taxonomy-templates/#example-list-all-taxonomies-terms-and-assigned-content
# Most of the time you’re only searching for one thing, so this might be adequate for most situations.
# I’ll have these appear as the “default” search results if you don’t search for anything.
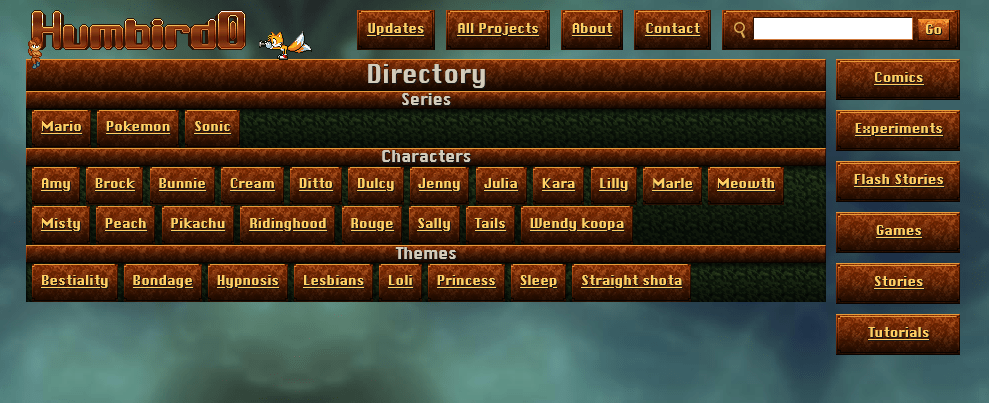
#Search keyword buttons
# My old website had a really handy search menu for touch-screen users. You just click the keywords that you want to add to your search. It was inspired by Booru websites. But this one’s prettier.
# I want my new website to have something similar. Now… how am I going to create a list of all the search terms? Oh wait, I already did! That’s the default search results.
# I’ll just make that a separate file so I can use it for both the non-javascript search and for the javascript search’s keyword buttons. I’ll just stick it in an iframe so I can display it wherever I want.
# Hmm… would this file be called a “directory” or an “index?”
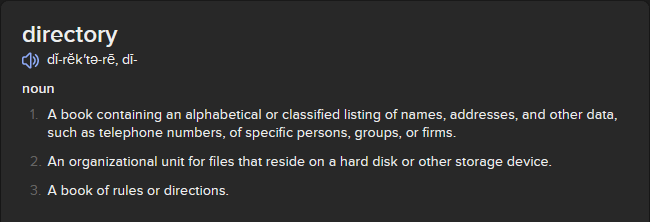
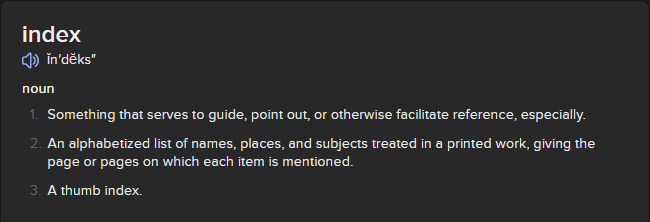
# So if I understand this right, a “directory” is a standalone book, while an “index” is part of an existing book. I guess my list of search terms is probably an “index.”
# Huh, would you look at that… I already gave it the correct name by accident. It’s almost like the internet itself was designed for documenting things or something.
#Keyword toggle buttons
# Okay, so how do I change the behavior of these keyword links to act like toggle buttons?
# I need the outside page to tell the iframe to act differently. But if the iframe is still in the middle of loading its HTML page, there won’t be any javascript inside of it to receive the message. So I need a way to detect when an iframe has finished loading first.
# Oh good grief, browser JavaScript has three load events!?
# Soo…. which one is the real one? Fuck it, I’ll just try ’em all and see which ones actually work.
# Okay, the “load” event fired, and the other two didn’t. Here’s the solution.
// This <script> must be placed somewhere after the iframe element itself.
var iframe = document.getElementById("directory");
iframe.addEventListener("load", function( evt ){
var iDocument = evt.target.contentDocument;
// get all link elements within the iframe
var all_iframe_links = iDocument.getElementsByTagName("a");
console.log( all_iframe_links );
});// after iframe has loaded
# Now let’s see how I can send messages between HTML files. postMessage is probably the solution.
# Okay, postMessage technically works, but… the iframe has to respond to all messages using a single onmessage() and then check what kind of event they are. Not exactly efficient.
# Screw it, I’ll just use normal events instead. I mean of course JavaScript would have two different ways to send messages.
# Outer page:
var iframe = document.getElementById("directory");
iframe.addEventListener("load", function( evt ){
var iDocument = evt.target.contentDocument;
iDocument.dispatchEvent( new Event("keyword_mode") );
}
# Inside the iframe page:
// react to "keyword_mode" event
document.addEventListener( "keyword_mode", function( evt ){
console.log("iframe detected 'keyword_mode' from its document");
}
# Okay so when this page goes into “keyword mode” I want all the links to stop acting like links and send “toggle” events instead.
// react to "keyword_mode" event
document.addEventListener( "keyword_mode", function( evt ){
console.log("iframe detected 'keyword_mode' from its document");
// change all links into events
var links = document.getElementsByTagName("a");
for(var l=0; l<links.length; l++){
var link_elm = links[l];
// disable normal link behavior
link_elm.href = "javascript: void(0)";
// add event behavior
link_elm.onclick = toggleKeyword;
}
} );// react to "keyword_mode" event
function toggleKeyword(){
// Get the text inside of this element
var value = this.text.toLowerCase();
// announce this
var new_evt = new Event("toggleKeyword");
new_evt.value = value;
document.dispatchEvent( new_evt );
}// toggleKeyword()
# Then I can just have the outer page detect those toggle events like this:
// react to "toggleKeyword" event from iframe
iDocument.addEventListener("toggleKeyword", function( evt ){
console.log("parent detected 'toggleKeyword' from iframe");
console.log( "value:" );
console.log( evt.value );
});// react to "toggleKeyword" event from iframe
# Yeah I know I could have just put all the code in the parent page and mutated the iframe without all of this back-and-forth. But programming experience tells me that mutating stuff from the outside is generally a bad idea, because when you later modify something inside you don’t know what external code is going to break. So instead of a hidden external hack, make it a visible internal feature.
# Anyway, all that’s left is to make the search box react to these events by adding or removing keywords, and then make this iframe appear whenever you click the search box no matter what page you’re on.
# Of course if you’re already viewing the search results, it might be convenient to have them update in real-time like my old website’s search engine does. Hell at that point I could even add some fun animation too.
# But let’s take a step back. This website is supposed to replace my old website. So are these keyword buttons better than the old ones?
# Maybe I should use the same 3-state buttons as my old website so that touch users can subtract search terms.
# As cleverly elegant as it seems to repurpose the HTML of the directory page, I should really use radio buttons for this because they represent what’s actually happening, and it will also look better too. My old website styled the radio buttons to look like 3-state buttons that touch-screen users can use to include or exclude words from a search. And because they’re actually radio buttons they behave the way keyboard users expect so you can use arrow keys to switch between their states.
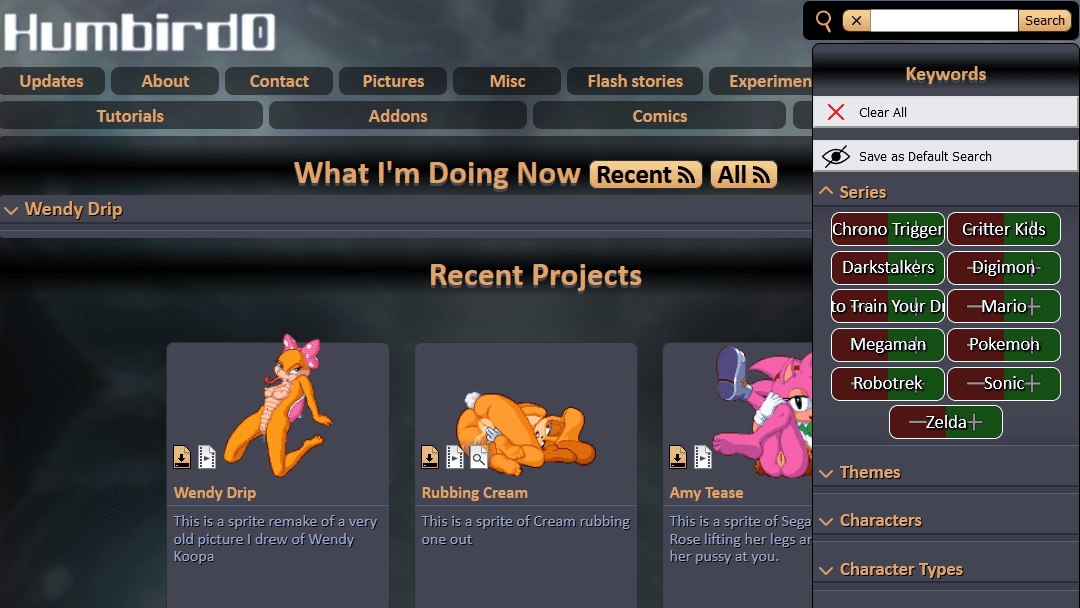
# Let’s start by just copying the raw HTML. I can figure out how it looks later.
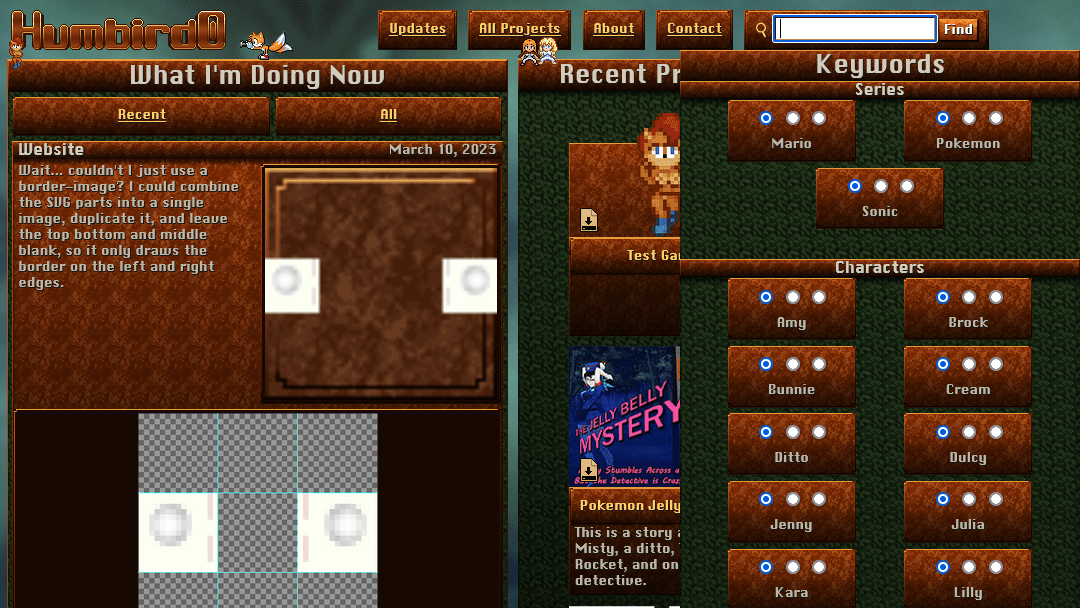
# Now to program the behavior of changing them with mouse or keyboard.
# Now that they’re acting right, let’s make them look right.
# And of course this would not be an improvement if it didn’t also have real-time search like my old website did.
#Thumbnail images
# Okay, I just re-added my imageZoom JavaScript from my old website. It’s just an optional convenience that lets you view a full-sized image without having to leave the page.
#
But…
I forgot that I often use small thumbnail images that link to full-size pictures. ImageZoom will display whatever the link is, but I need to modify my Hugo templates to create these links.


# So far I’ve been using a render hook to just wrap images with links to the same image.
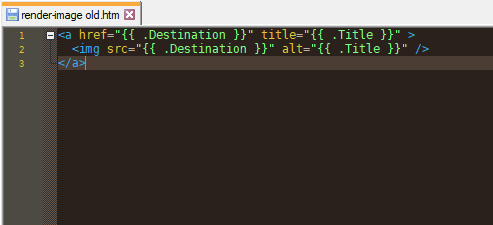
#
Let’s modify it to use a small thumbnail file for the IMG tag. I tend to put a _t at the end of all my thumbnail filenames. So I’ll take the URL of the picture, chop it in half where the .jpg extension is, insert a _t at the end of the filename, and then re-attach the extension…. and then check if that file actually exists, so I don’t accidentally link to non-existent files.
#
Basically I want to change:
folder/file.jpg
Into:
folder/file_t.jpg

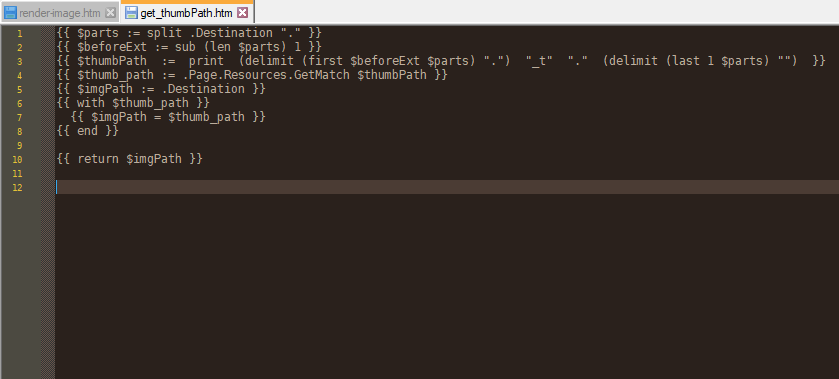
# GetMatch checks if the file exists.
# with acts kind of like an IF statement, except it doesn’t complain when a variable doesn’t exist.
# Hugo doesn’t have a “lastIndexOf” function, so I have to split the path into an array and then stitch it back together using a “print” command. Since this takes a bunch of lines I’ll just throw it into a separate “partial” that I can re-use whenever I want to generate a path to a thumbnail.
# Hugo can supposedly even generate thumbnail images for you, but I prefer to create them myself because I’m a control-freak who likes to crop things a certain way.
#404 Error - Page Not Found
# Recommended way.
Create /layouts/404.html
Create /content/404.md
Set its front-matter to:
URL: 404.html
#
… which doesn’t actually work.
Lies! Slander! Fraudulence!

# So… here’s what does work.
Create /layouts/_default/404.html
Create /content/404.md
Set its front-matter to:
URL: 404.html
layout: "404"
#Detecting numbers in string variables
# While adding one of my comics to my website I ran into a tricky problem. I needed Hugo to detect whether or not a variable could potentially be a number. Why do I need this? For my comic pages.
# When I create a comic, I store each image’s page number as its alt-text.

# I want Hugo to wrap each picture in a link that jumps to the next picture in the sequence. So I need to be able to add +1 to these. But not all pictures on my website has numbers in their alt-text, so I need to detect whether this is a number before I attempt to add +1 to it, otherwise Hugo will crash.
# I figured out a clever way to do this. Compare the string to itself as upper-case vs lower-case. If they match then it doesn’t contain any letters, and I can assume it’s a number.
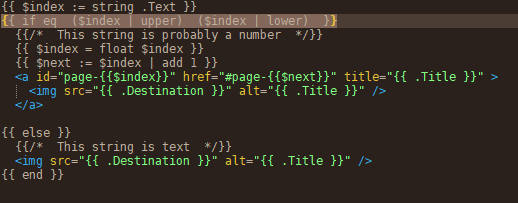
# Now teeeechnically any alt-text containing only punctuation could mess this up, but there’s no reason why that would ever happen.
# Now you’re probably asking the obvious question. Why not just directly write the number for the next page instead of making Hugo add numbers to strings? I could, but I want to use Typora to edit all my markdown files because it supports drag-and-drop and automatically adds alt-text based on each image’s file name. This means I can drag-and-drop a hundred files and it’ll automatically write the alt-text for each of them, which takes seconds instead of hours.
# It’s not about alt-text or Typora. If I told Hugo to read the image filenames instead, they would still be strings, and I would still need to check whether or not they contained numbers. Using the alt-text just saves me the trouble of chopping off the file extension first.
#Pokemon is too powerful
# Okay, now I need to actually add all my projects to the new website. I created a converter program to get me most of the way there. It reads my old project JSON file and writes out a bunch of content markdown files to each project’s folder. My website editor can feed those to Hugo to create HTML pages. So it’s mostly a matter of copying each project’s folder and manually adding a readme markdown file.
# Huh? Why did Hugo’s server crash after I added my Pokemon game?
# Oh… that’s why. I ran out of RAM.
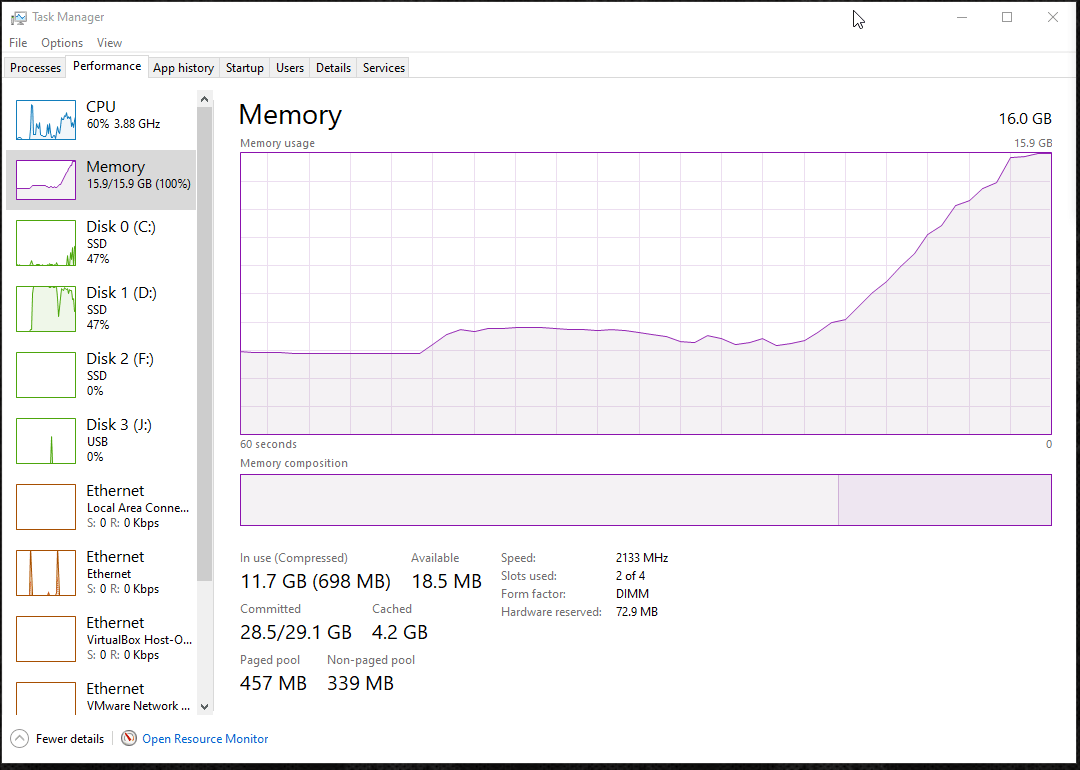
# I wonder if it’s because of the “! SRC” folders inside of each project’s folder? That’s where I keep all of their Photoshop files and uncompressed AVI videos that I use to create their thumbnails and videos. I told Hugo to ignore these folders but maybe its server still puts all those files into RAM?
# Well, let’s try a test. I’ll remove all the “! SRC” folders and see if Hugo’s server runs any better… nope. It still runs right up against the limit. It doesn’t crash if I don’t have many other programs open, but it still seems to get awfully close.
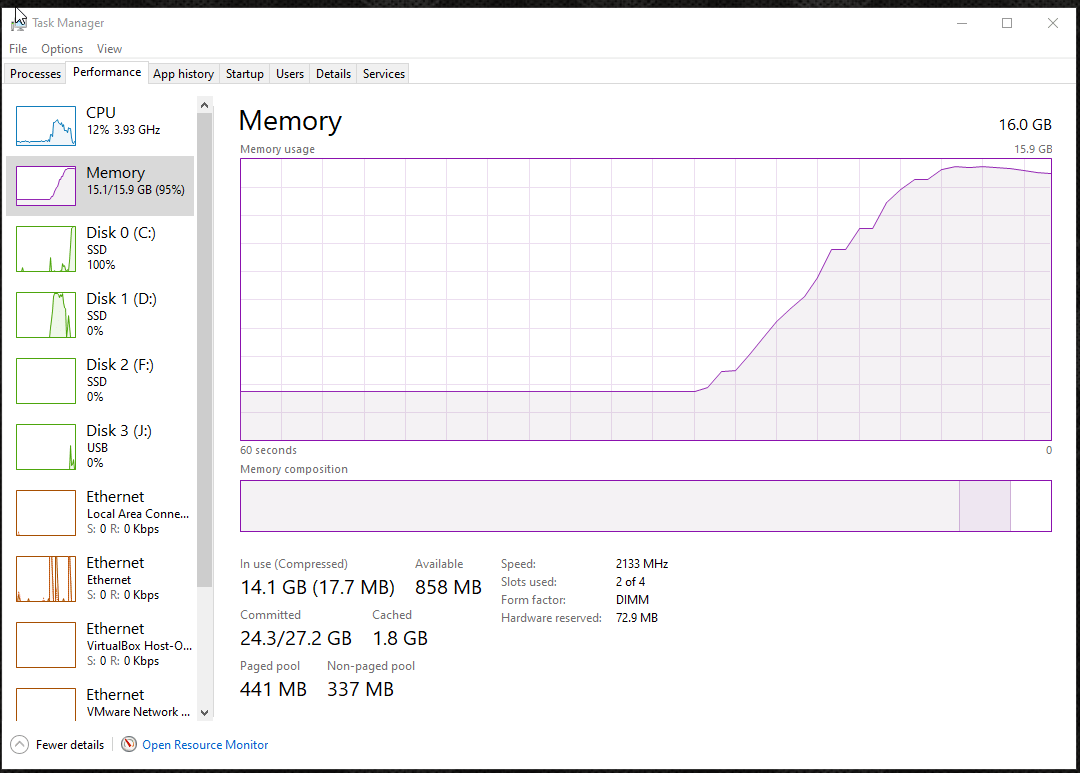
# Removing the source folders made no difference so I guess Hugo really is ignoring those folders like I told it to. My website is just that chunky. I guess, that’s what I get for uploading video tutorials, entire games, and level editors.

# It’s not really a problem. I could just use a different test server that reads files from the hard drive instead of trying to put everything into RAM.
#Yo Dawg! I Got Descriptions in My Descriptions!
# No, but this could be a problem. I’ve been putting off adding one of my games because it’s actually a collection of 26 game experiments. My old website had pop-up descriptions for each of them that displayed when you hovered over them. How on Earth will I convert THIS into markdown!?
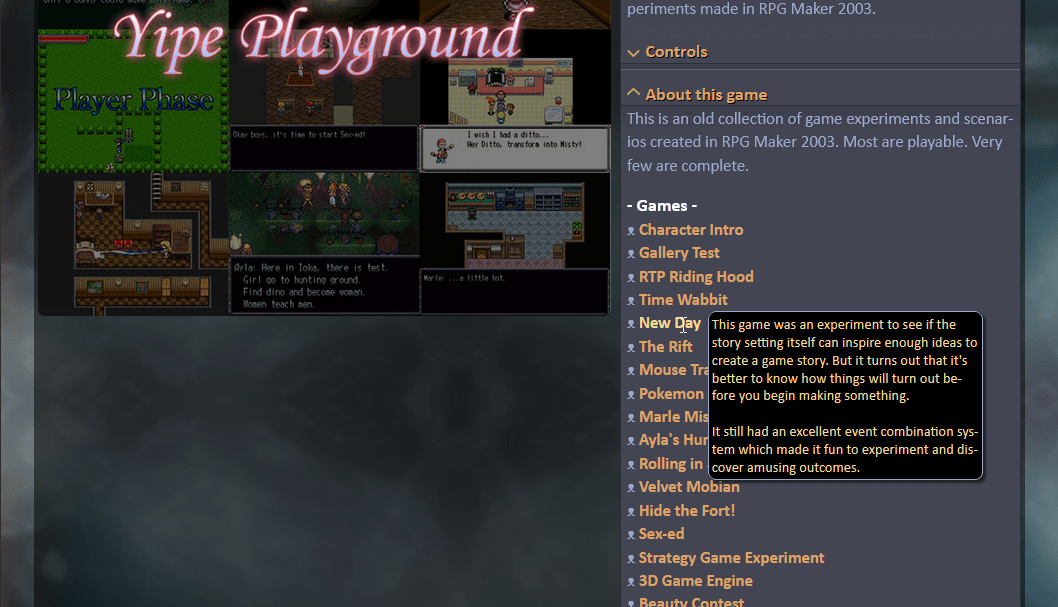
# So I guess the first step is to take a step back and ask myself, what do I actually need this to accomplish?
- I need a list of games
- I need a description of each game
# Okay, so if I look at the extended markdown syntax (which Hugo mostly supports) it looks like it’s actually possible to create definitions lists. That could accomplish the 2nd goal, but it would look pretty cluttered and hard to see simply how many games there are because the list of names would have all these descriptions crammed in between them.


# Of course it would be trivial to second list with just the names of each game. But now how can you easily look up the description of the game you’re already looking at without having to manually look for the matching name in the definition list? Use links? If I could manually add anchors then the simple list could link to the detailed list. Is there a way to do that?
#
Actually… yes. With footnotes!
(Yeah, those crusty old things only used by old researchers in physical books)
No really, think about it. In HTML and markdown a footnote is a link that jumps down to another part of the page. That’s exactly what I want!
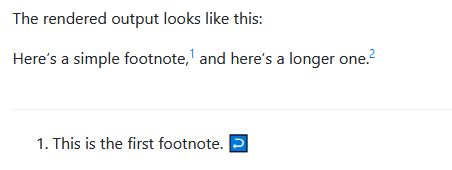

# I’ll put the link at the beginning instead of the end, that way each game is “numbered” I just think it looks better that way. But it does look kind of janky with bullet points too.
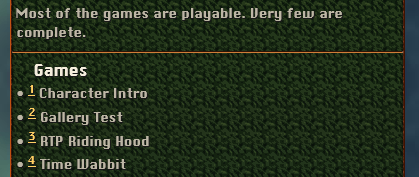
# Let’s just leave out the bullets. I suppose it’s no longer technically a list in the semantic machine-readable sense. But is that really such a critical thing? Footnotes are machine readable, and a bunch of footnotes in a document are conceptually a list. I dunno, that’s all pretty theoretical. I don’t know how Google’s search engine actually interprets all this semantic stuff. It probably ignores obscure things like footnotes that nobody uses… but anyway it looks nice.
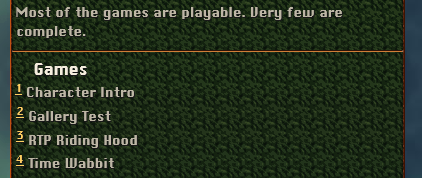
# Okay, apparently Hugo turns the footnote descriptions into an actual list. And since I included each game’s title in them too, there’s nothing to worry about. This is the complete information package.
# Hugo even adds these convenient return links. This turned out way better than I thought it would!
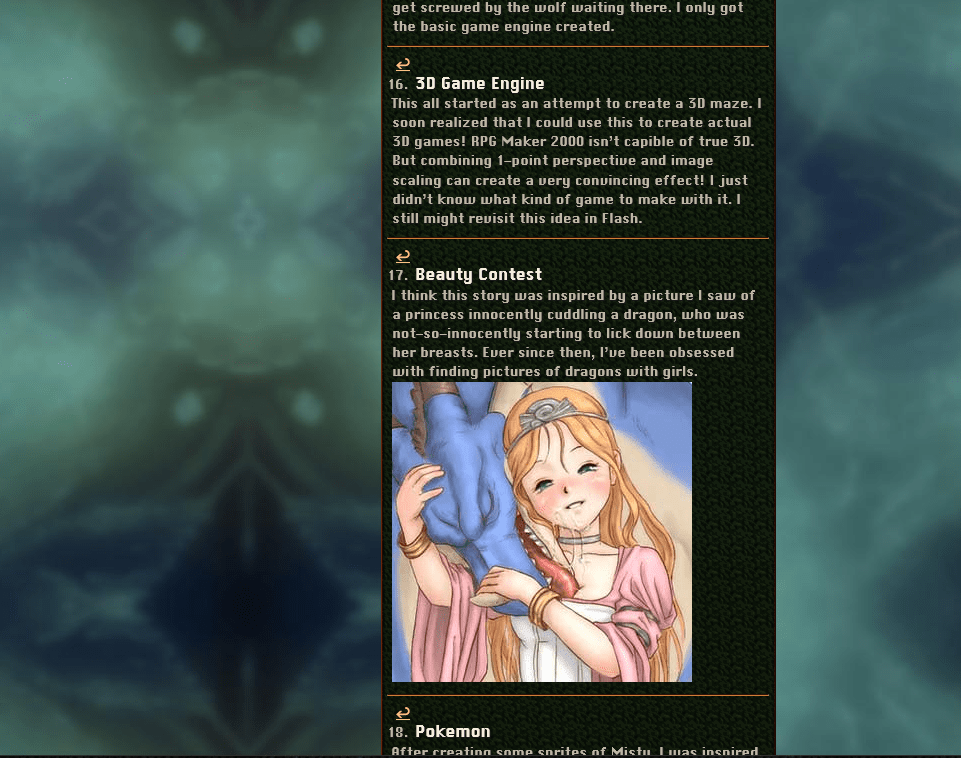
# Besides the old website’s “pop-up” descriptions always got cut-off when you tried to view them on a phone. Sometimes “primitive” designs work better. The funny thing is that I didn’t even design my CSS to accommodate this. It just automatically looks nice because HTML is designed for combining.

#Looking Back on the Process
# When I look back at the process of copying everything over to the new website. Some things were harder to copy than others. But not the things you might expect.

# Sure, simple projects containing a single picture or video were easy. I wrote a converter program to generate simple markdown files for them to display these things. Most of the games are just a picture and a download link.


# All the downloads are stored in each project’s metadata. Which is also just JSON. In fact I’m still using (mostly) the same JSON format to handle the metadata for the new website. That side of things hasn’t changed. But I decided to rewrite my metadata editor again from scratch because I didn’t want to stare at my sloppy old programming. I theoretically could have skipped doing that and just made slight alterations instead.
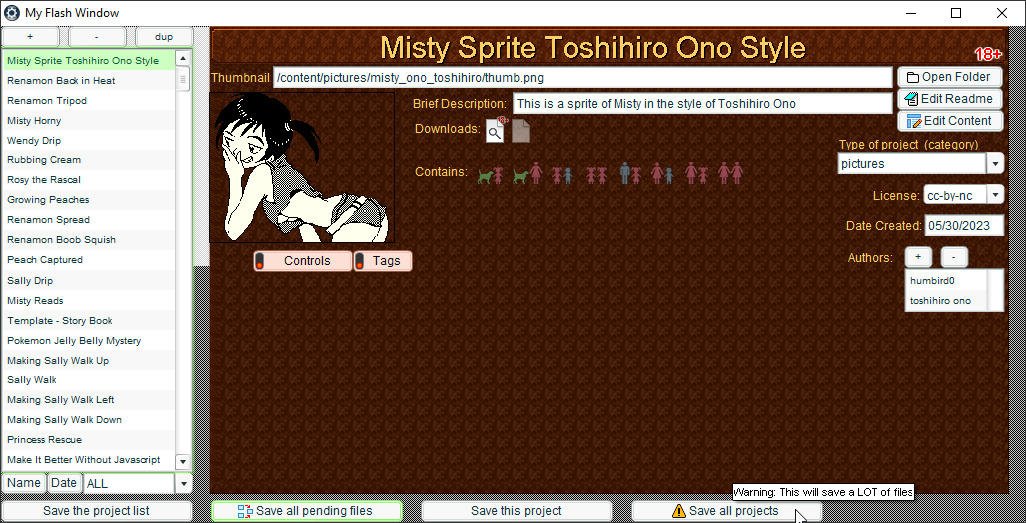
# Most of the blogs were easy to convert. That might seem surprising since they’re the longest stuff on my site. But what made that easy was how I stored them. Almost every article was originally just a bunch of separate social media posts on Twitter or Mastodon, which I was managing with my Mastodon/Twitter cross-poster. That means I already have a JSON file with every post in it, and each post was tagged with the project it was talking about. So it was trivial to add a feature to my cross-poster to look for every single post about a specific project and just dump all of them into a single MarkDown file ready to upload as an article.



# The hardest part was actually the project descriptions. I don’t mean the one-liners you see under the thumbnails. I’m talking about the “More Info” tab explaining the inspirations and discoveries behind each project. I ended up manually re-creating each of these from scratch for almost 300 projects. And that’s where most of the time went. Maybe I should have just parsed the existing HTML files as XML and tried to look for patterns. That probably would have helped. But part of the problem is that these were all hand-written HTML, and XML parsers are more picky about syntax than web browsers, so that was not likely to work smoothly. On top of that, I might have presented some things in weird custom ways in some of the files.
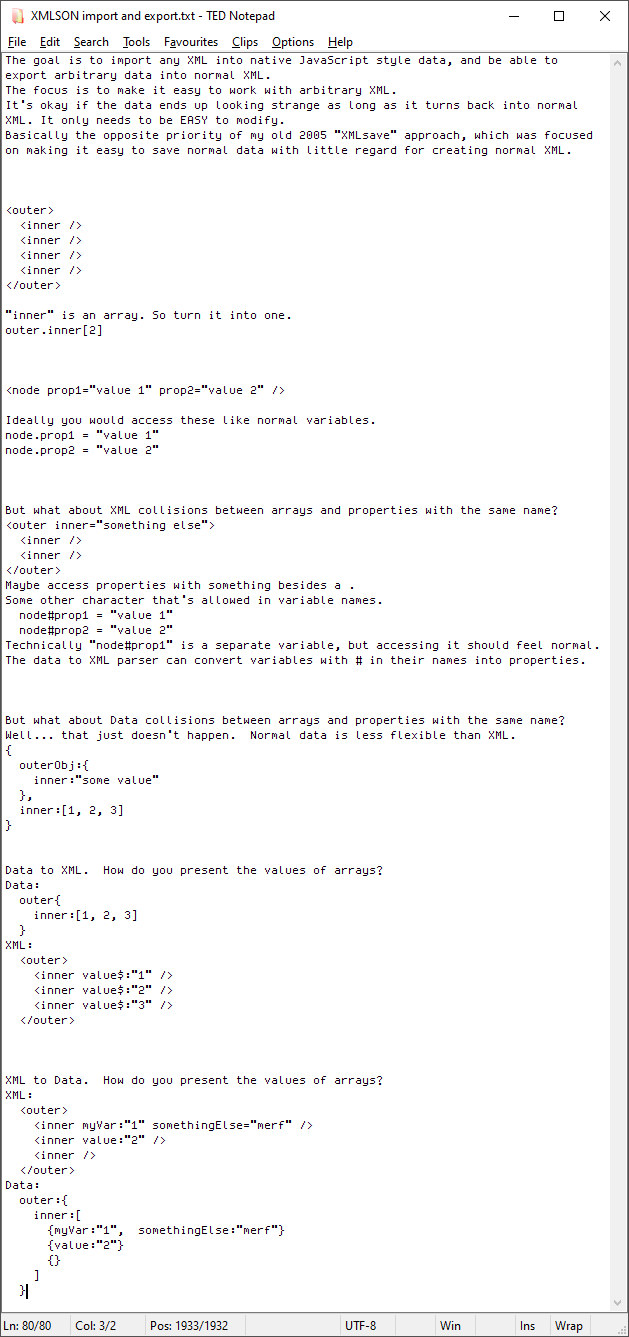
# Will I have to go through all of this again in another 10 years when I decide to redesign my website again? Maybe… Hopefully it will be easier. Using MarkDown is supposed to force my content into a simpler and more consistent format. Hugo is a single self-contained EXE so it should be possible to run it 10 years later to read all of this and spit out something else.

# Alternatively I could take the consistent and program-written HTML of my website and maybe parse that… but I probably won’t. XML is a pain in the butt to work with at a programming level. (although I recently had an idea about a way to maybe import and export XML to data and back like you can with JSON)
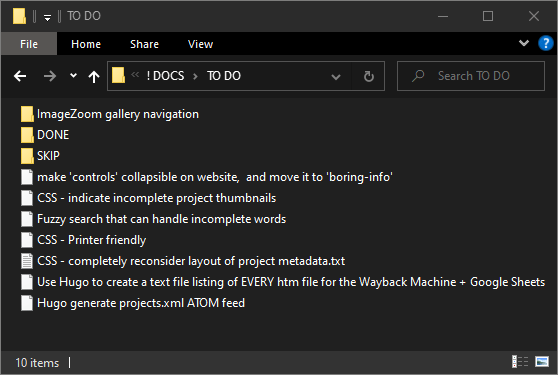
#I think the website’s done… maybe? … probably??
# Well it’s feature-complete, the automatic uploading should theoretically work, and I my TO DO list only has minor adjustments in it that I can put off for later.
#
So do I pull the trigger now and completely replace my entire website?
Er… later. I’ll do it later.
I’ll save it for my day off, so I have time to improvise things when something likely goes wrong.


# Okay, I’m home from work. I have tomorrow off. It’s time to replace my entire website. I’ll just do a couple pre-flight checks and launch this sucker!
# Actually there’s very little to do. All I have to do is tell WinSCP to sync the new website’s “public” folder to the server and… done. Most of the actual project files won’t even move. It’s just the HTML, CSS, and JavaScript I’m replacing. And the original URL to access the website will stay the same.

# By the way, WinSCP has been an amazingly useful program. Aside from being able to watch folders and automatically sync them like DropBox, and being fully scriptable, it’s been my favorite “FTP” program for about a decade now. It’s freeware, but after all this time I should probably donate as a way to say “thank you”
#
Let’s see… is it worth one Big Mac… or five?
Hell, let’s make it 10 Big Macs for 10 years of service.
#The Problems I Expected
# Sure enough, things didn’t go perfectly. But much better than I expected. Apparently Hugo converts all folder and file names to lowercase by default. My local NodeJS test server was resolving these differences transparently so I never knew it was happening. But the real server is case-sensitive. So pages are “missing” if a link points to a file name with upperCase letters but the actual file is all lowercase.
# This seems to affect only a few projects, but since it doesn’t always affect the thumbnail pictures it’s hard to be sure exactly which ones, so the best approach is to rename all the source files to all lowercase, then give Hugo a minute to rebuild everything, and then sync the website again.

# … OR
# I can just TELL Hugo to preserve caseSensitive URL’s with a simple change in its config file.
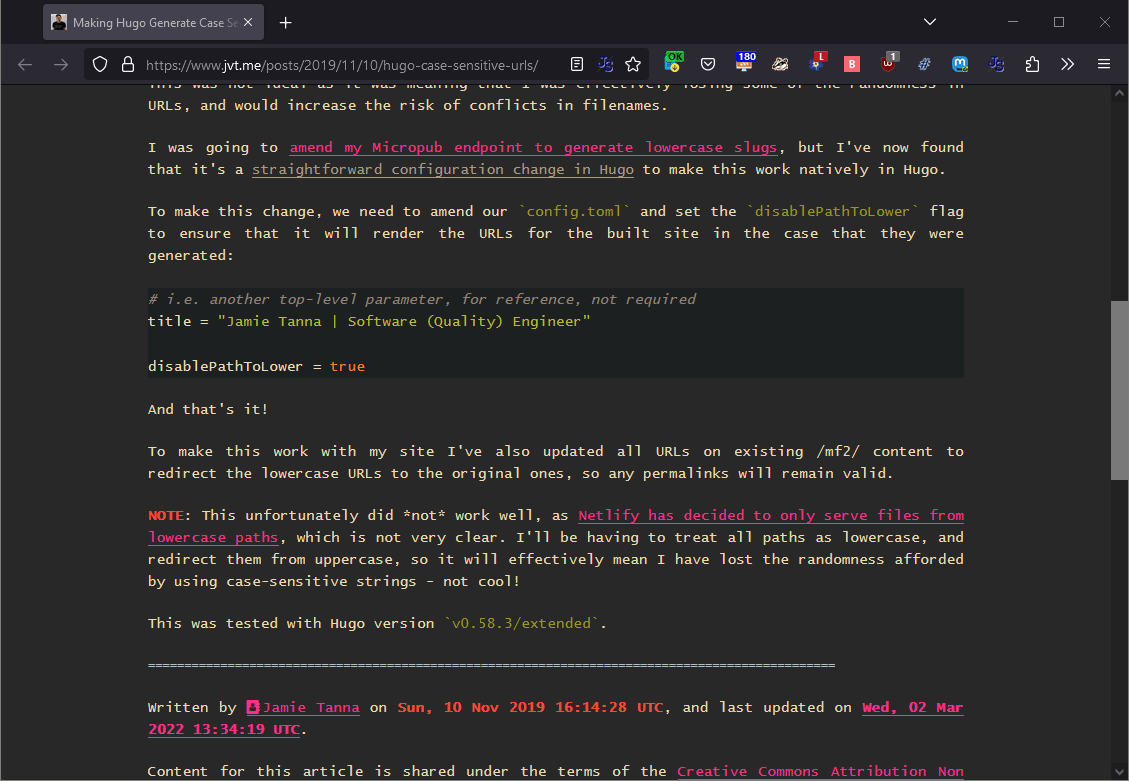
# Whoops! I gotta be careful with the synchronize feature. Do NOT activate “delete files” and “existing files only” at the same time.


{kind=link}
# … so now I have to wait 3 hours to restore the entire website instead of just 20 minutes to replace only the HTML files like before.
#
Okay, everything seems to be working now.
… except RSS feeds.
Well they do work but they’re not loading their CSS files. Apparently I accidentally used a root-relative path of /rss.css which won’t work in RSS feeds. You have to use full paths like http://www.humbird0.com/rss.css instead. If you think about why, it makes sense. An RSS feed gets downloaded and viewed separately from the website it came from, so the paths have to be full URL’s. Anyway, it’s an easy fix.
# One silver lining is that if anything is missing it gives me a chance to test my 404 page’s automatic Wayback Machine look-up, which will link you to what used to be there.
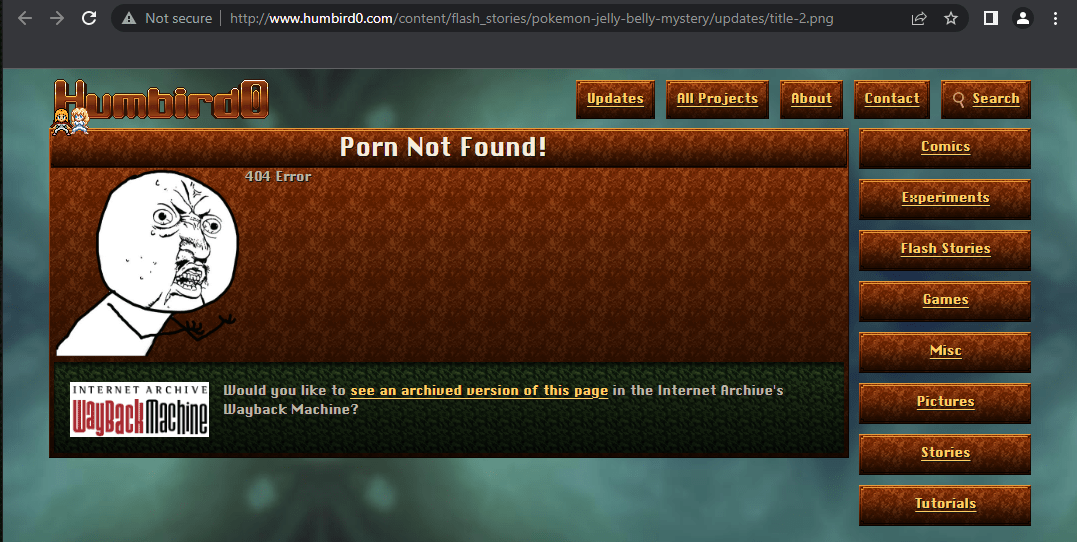
#Biting the feeds I’m handing to it
# The only other weird bug is the updates page sometimes shows “map” in the text. But only when there are multiple paragraphs. In Hugo, a “map” is basically an object. So apparently the text of this feed is sometimes treated as a string, and sometimes treated as an object.
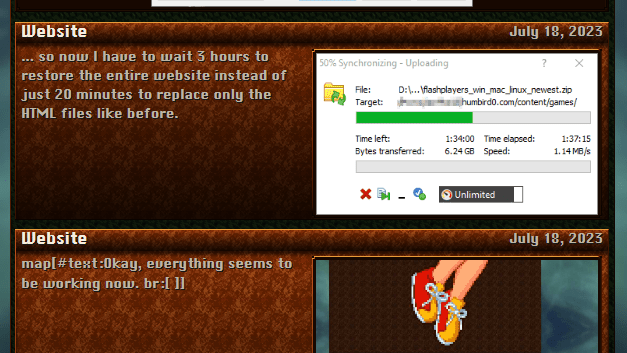
#Fixed it!
# Okay, so I took another crack at the updates page with the random “map” stuff in the text, and managed to fix it. So let me just cut to the chase and give you the solution. If you want Hugo to grab raw HTML from an ATOM feed, there are 2 steps:
- Store the HTML in escaped form in the
<summary>tag.
 The correct way to store HTML in an ATOM feed.
The correct way to store HTML in an ATOM feed. - And use this to output the raw contents of the
<summary>tag.
~
 The correct way to read ATOM feed with Hugo.
The correct way to read ATOM feed with Hugo.
#So what’s going on? Why does this work?
# Escaping the HTML prevents Hugo from parsing it, so it remains a single blob of text. That’s good!

#
But Hugo does parse the <summary> tag that’s wrapping it.

# Which is inconvenient because it becomes an object containing variables. But one of those variables contains the juicy blob of text we want, so it’s not really a problem.
#
 This line extracts the escaped HTML stored in the
This line extracts the escaped HTML stored in the #text variable.
#
| safeHTML }} This tells Hugo not to sanitize the text, and just output everything as-is. And that… somehow… un-escapes it. Well I don’t know why, but it works. So that’s good enough for me.
#Why didn’t it work before?
#
Well in my previous attempts I was trying to access the text from the raw unescaped XHTML stored in my <content> tag, but at the end of the day the hard truth is that XHTML just isn’t valid XML, even when it’s written correctly. Because in XML you’re never allowed to put tags in the middle of text. Whereas in HTML you’re constantly putting <a href> links and <img> images in there. The only way for XHTML to be truly valid XML is to close every <p> paragraph tag before adding any links or images. And realistically… that never happens.
# So in my next attempt I wondered if there might be a way to store arbitrary text inside XML without Hugo trying to parse it. Well it just so happens this is exactly what CDATA is for. But I was still just getting a “map” with all this junk.
#
But I noticed that if I used  then Hugo would actually output everything… but then also display the word “HTML” at the end. This was tantalizingly close to correct.
then Hugo would actually output everything… but then also display the word “HTML” at the end. This was tantalizingly close to correct.
#
But then on a whim, I tried accessing the <summary> tag instead of the <content> tag. Summary contained escaped HTML instead of CDATA, and that happened to work too. So apparently I didn’t need CDATA at all. Escaping the HTML accomplishes the same thing.
# But either way, how would I get rid that extra “HTML” word being displayed at the end? Apparently there was an extra variable, and I wanted to skip it.
#
Now… about that I was using. In Hugo “range” loops through arrays or objects. When it was displaying the word “map” before, that was Hugo telling me that it turned .summary into an object after it read the XML file. Objects contain variables. So if I could just figure out the name of the variable I could get the content I wanted.
#
But when I looked at this output, it seemed like the map/object contained a variable called “text”… I think? But when I tried to access the variable using  I got nothing. A complete blank. So maybe I got the name wrong? If only there was some way to make Hugo list the names of all the variables in an object.
I got nothing. A complete blank. So maybe I got the name wrong? If only there was some way to make Hugo list the names of all the variables in an object.
# Well… apparently there is.
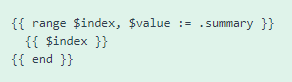
# And what variable names did I see?
#texttype
#
Wait, hold on… that # symbol is actually part of the variable name!? I just assumed it was some weird Hugo “Go Template” syntax crap I didn’t understand yet.
# That post also mentions using the index function to access variables inside of maps, so what if I tried this?
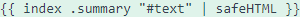
# Bingo!